
.PNG)
Disclaimer
I am not comparing AWS Glue with Lambda. In perspective, we work with data processing, and I would prefer to use AWS Glue. We will see case-by-case when to use AWS Glue or Lambda.
Overview
When talking about serverless, most of us will agree Lambda should be on the top list. But hey mates, sorry to say: it’s old. I want something fresh, tempting, and even longer without a time limit.
Yeah, here I will try to tell you about a new experience with an AWS Serverless-based service with rich features. Aaaand now, ladies and gentlemen, please welcome our younger and hotter service that lets you run code without a limit time! They are awaiting your applause and congratulations in the comments!
AWS Glue
A serverless environment to extract, transform, and load (ETL) data from AWS data sources to a target that:
- Provides manageable data processing and centralizing from multiple data sources
- Supports Python and Scala programming languages
- Supports event-driven architecture
- Supports visual data flow with rich templates
- Less code and adjustable
- Let’s see what else!!
This time, I will demonstrate one basic use case which is migrating data from S3 to DynamoDB. There is data in CSV format that’s stored in one S3 bucket. Then, with AWS Glue we will do these scenarios:
- Data sourcing
- Data mapping
- Data storing in DynamoDB
Here I will use Python for the logic code, are you guys still excited? Grab some more coffee and keep reading!
Start Glue Job:
Prerequisites
First of all, let’s prepare one S3 bucket (Follow this to create the s3 bucket) and the CSV file. For the CSV data, we can use this dummy:
Also we will create the DynamoDB table as a data target. In this case, set UserName as the partition key and Email as the sort key. Once they’re already prepared, we are ready to start the initial job flow.
Next, initialize the IAM Role for the Glue Job:
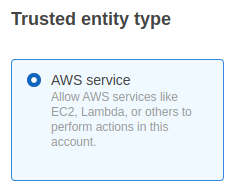
- Create a new IAM Role with AWS Glue as a trusted entity
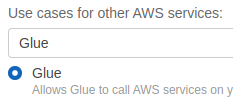
- Next, add initial Permissions from the existing template
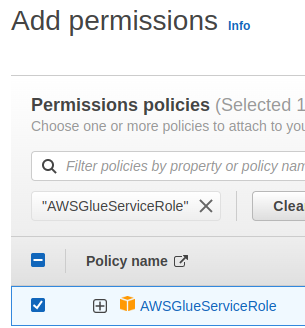
- Then put the role name; Create role
- Once the role is created, add a new inline policy that has permissions to both S3 bucket and DynamoDB table we created:

Now we’re ready to jump into the Glue Job
Initial Glue Job
It’s so easy to create a new job with Glue. The glue job will generate the initial code, so we will just improve it as needed. From the AWS console, I will search the service name AWS Glue and find the Jobs menu on the left panel. Clicking it will load a new page to Glue Studio.
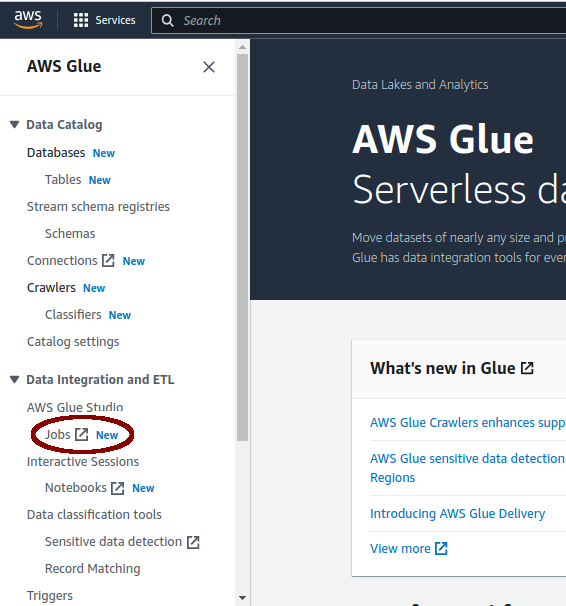
On the Glue Studio page, we will set up the initial job flow by selecting the Visual with a source and target option, then let it define both source and target. Glue supports different data channels, but for now I’d prefer to focus on starting with S3 for the data source and DynamoDB for the target. On the Glue Studio page, we will set the source to S3.
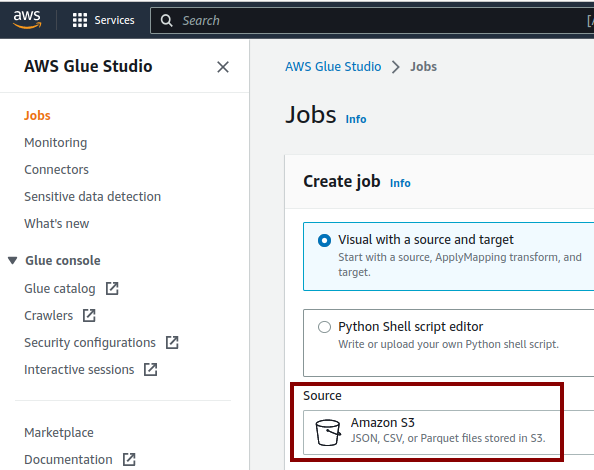
And use Choose later on the Target as there is no DynamoDB option on the Target list.
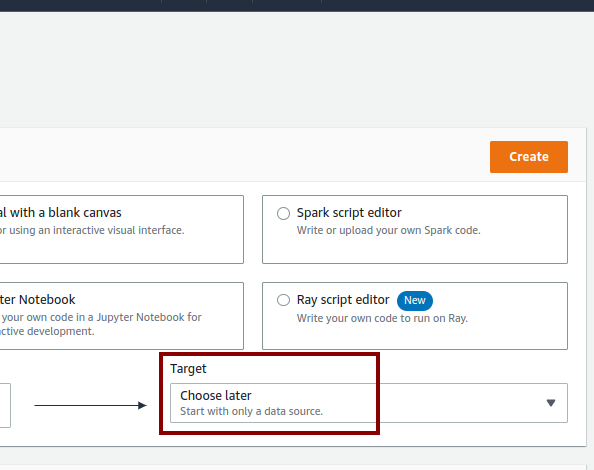
Just click on the Create button, it will show an initial diagram with a node Data source; that’s the S3 bucket. We can design various workflows on this diagram.
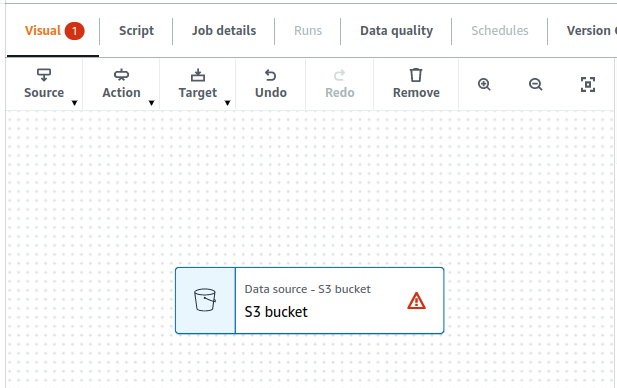
Click that S3 node to edit the configuration on the right pane per these requirements:
- S3 source type: S3 location
- S3 URL: The bucket/folder/file path e.g s3://my-glue-job-bucket/, s3://my-glue-job-bucket/my-data/. We can set the URL to the direct object/file path for example s3://<bucket_name>/folder/filename. For now, let's set the URL to the bucket name only
- Data format: CSV
- Delimiter: Comma (,)
- Quote character: Disable
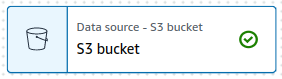
Let's keep the rest fields as they are and verify the config updates by clicking the Infer schema button. If the S3 node source displays green check the initial config is verified/correct.
Update Job
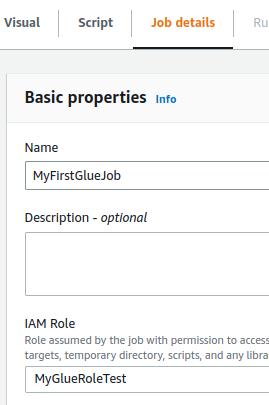
Now we move to the Job details section, put the job Name, select the IAM Role we created, and Save.
We’re ready to update the initial job code per our use case. Go to the Script section and click Edit script. Put the following code into the job editor:
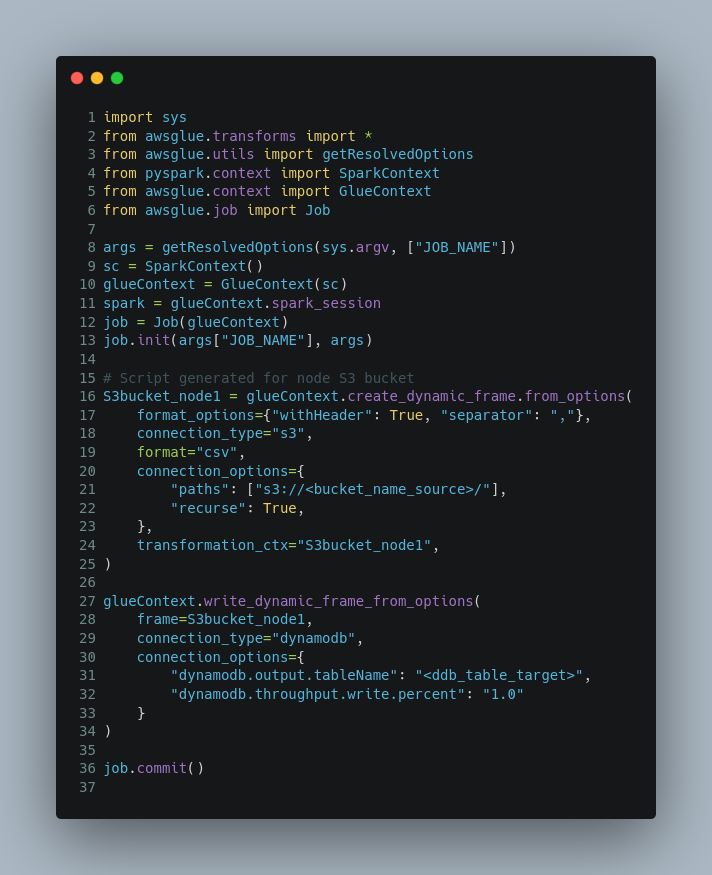
Let’s introduce the code piece by piece!
On the initial code, it would be displayed like this:

First of all, the glue job imports some required libraries and we can see it’s using Pyspark API which is suitable for distributed computing, real-time, and large-scale data processing. In a later blog post, we will work much with Pandas API where PySpark is a good language to learn to create more scalable analyses and pipelines.
Line 16 - 25, is populating CSV data from S3 and converting it to a dynamic frame. We’re able to recursive multiple CSV files by enabling line 22. The recursive will retrieve any CSV files under defined paths including existing subfolders. For more information on the dynamic frame, jump here.
So we have raw source data as a dynamic frame object now (S3bucket_node1). Next lines, we will store them in the DynamoDB table:
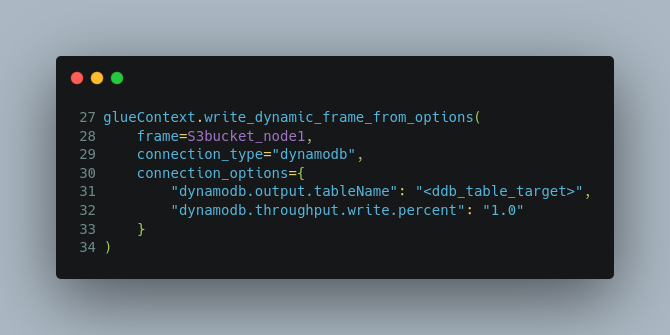
The last line, job.commit() will update the state of the job bookmark.
Well, let's save the updates and click Run to see the result. To monitor the job process, go to the Runs section and we will see the running state with some information. If we want to print out some info for debugging to the Cloudwatch logs, just use the python print() API on the code. So then from the Run section find out the Output logs link.
Conclusion
I found a very simple way to migrate millions of data from one source to another node. I’m not even familiar with how to work with Python. AWS Glue provides a friendly interface for us to perform data lake processing. Beginner? It doesn’t matter! If you’re still excited to dive deep into AWS Glue then stay tuned for the next part! For any comments or questions, find me on Linkedin.
Links
https://docs.aws.amazon.com/prescriptive-guidance/latest/serverless-etl-aws-glue/welcome.html



%20(1).svg)

.svg)









.webp)