

Imagine traveling to a country for vacation and not being able to converse in the local language. It can be difficult, but not anymore!! Travel easily with your own custom built translator and transcription app that you can open and use without learning a new language. Taking inspiration from the above scenario, let us build two applications using AWS: a text-to-text converter app using AWS Translate and a speech-to-text application using AWS Transcribe.
App 1: Text-To-Text
When we travel to a country, it is common to feel confident without knowing the local language. It seems arrogant, right? This confidence is not in our knowledge, but rather in our translator apps, which have been trained with plenty of data. The presence of translator apps can enhance our experience of a city without worrying about communication in the local language. Imagine you visited France, and you wanted to start a conversation with the local people or with a shop owner (to make them feel you know French). You don’t need to purchase a book on “How To Learn French in 30 Days”, and start reading it on the flight. Instead, you could open the translator app, enter the text or source language and it will translate the text to the target language, which is “French”. All this seems to be fun right? Why don’t we take inspiration from this scenario and build a simple application using AWS services? Let’s dive into the process!!
User Perspective
By now you are well aware of the scenario, so instead of just diving into building an application, let’s take some time to break down the user perspective on how things work in the front end.
- User Opens the translator app or enters English to French Translator in Google.
- A web interface showed with the input, where the user can type in.
- User type
“How are you?”. - To the left translated text is shown in the French language.
Architecture Breakdown - AWS Translate
When we talk about translating text, AWS Translate rings the bell in my mind! It will be easier to implement the translation feature in just a few lines of code. As we are already familiar with the user perspective, let’s understand how we can build a simple application in the back end using AWS.
- When a User completes the text in English hit an API route
/translate-text. - A Lambda Function attached to the route was triggered, which calls the AWS Translate with the source and targeted language, along with the text in the source language!
- On a successful request, Lambda will return the translated text to the user!
Code Breakdown - Understanding AWS Translate
The architecture breakdown of the problem seems to be pretty straight forward right? Writing the code for the solution is much simpler with a few lines using the package! Here is the JavaScript code to utilize AWS Translate to complete the process of translation.
const { TranslateClient, TranslateTextCommand } = require('@aws-sdk/client-translate');
const translateClient = new TranslateClient();
/*
* This function will call the AWS TranslateClient with the params to convert text to target language
* @params { Object } translateParam - param passed to translate client to perform translation
* @returns { String } - returns the translated text
*/
const translateText = async (translateParam) => {
try {
const command = new TranslateTextCommand(translateParam);
const translationResult = await translateClient.send(command);
return translationResult.TranslatedText;
} catch (error) {
console.error('[ERROR] Error in translation', error)
throw error;
}
};
/*
* This Function will be calling the translateText function with the params which includes
* Text, Source & Target language for translation
* On Successful completion of the job it will return the translated text
* @params { Object } event - Event passed to the lambda
* @returns { Object } - return the translated text
*/
module.exports.handler = async (event) => {
try {
console.log('[INFO] Event Passed to the lambda', event)
const { text, sourceLanguage, targetLanguage } = JSON.parse(event.body);
// AWS Translate: prepare the translation parameters and call the translateText function to get translated text
const translateParam = {
Text: text,
SourceLanguageCode: sourceLanguage,
TargetLanguageCode: targetLanguage
};
const translatedText = await translateText(translateParam);
// Lambda Response: Return the translated Text
return {
statusCode: 200,
body: JSON.stringify({
translatedText,
}),
};
} catch (error) {
console.log('[INFO] Error in handler:', error)
throw error;
}
};
Writing a code to translate text from source to target language is quite simple:
- Importing the
TranslateTextCommandfrom the package@aws-sdk/client-translatewhich prepares the command for the params passed, - Then just call the function
TranslateClientto complete the translation process.
const translateText = async (translateParam) => {
try {
const command = new TranslateTextCommand(translateParam);
const translationResult = await translateClient.send(command);
return translationResult.TranslatedText;
} catch (error) {
console.error('[ERROR] Error in translation', error)
throw error;
}
};
IAM Permission - "Don’t you want your lambda to complete without any error?"
You might forget, but AWS won’t! It will be crucial to run lambda without any permission specified to call the Translate, because lambda requires translate: TranslateText permissions to successfully perform the translation job. Copy the below permission and attach it to the lambda before choosing the API.
{
"Version": "2012-10-17",
"Statements": [
{
"Effect": "Allow",
"Action": [
"translate:TranslateText"
],
"Resource": "*"
}
]
}All done, now you can use the API route.
App 2: Speech-To-Text
In a second scenario, what if you wanted to start a conversation by saying something in French and you used a text-to-text converter, but now they respond in French? You didn’t understand what they said and got confused about what to say in response, right? Now it’s making it a bit difficult to use the translator app. To tackle this problem you would normally open a speech-to-text app on your phone, right? Let’s build an application instead, which will listen to the user and then convert the speech to text.
User Perspective
- User opens the
speech-to-textapp on the phone or in Google. - Select the source language as “French” and start to record the audio.
- After completing, a request is made to convert the text to “English” is shown.
Architecture Breakdown - AWS Transcribe
By breaking down the user perspective, you can gain a better understanding of what should be implemented. Building a speech-to-text app could be done using AWS Transcribe, which is a recognition service trained with tons of data, and helps us analyze the audio and then translate the audio to the text. Let’s do a quick breakdown of the back-end flow:
- User opens the speech-to-text app, selects the source language, and clicks on the mic to start saying something in French.
- An API Request is made to the route
“/store-audio”, with information source and target language. - storeAudioFileLambda Function got triggered, which will generate a pre-signed URL to upload the file, along with that source, target language, and transcribe job name is also stored as metadata, which will be used by the next lambda.
- Next, transcribeAudioLambda triggers an event successful of file upload, and then the transcribeAudioLambda function calls AWS Transcribe, with the params containing the source audio file, target bucket name, target language, and a transcribe job name.
- Once the Job is completed, AWS Transcribe stores the transcribed text in the target bucket as a JSON file.
- Next, another API request is made to the route
“/get-transcribed-text”, with the key provided from the previous API request as a response. - getTranscribedTextLambda will be invoked, which calls the s3 bucket to get the transcribed JSON file, after transforming the JSON, the translated text will be sent back to the user.
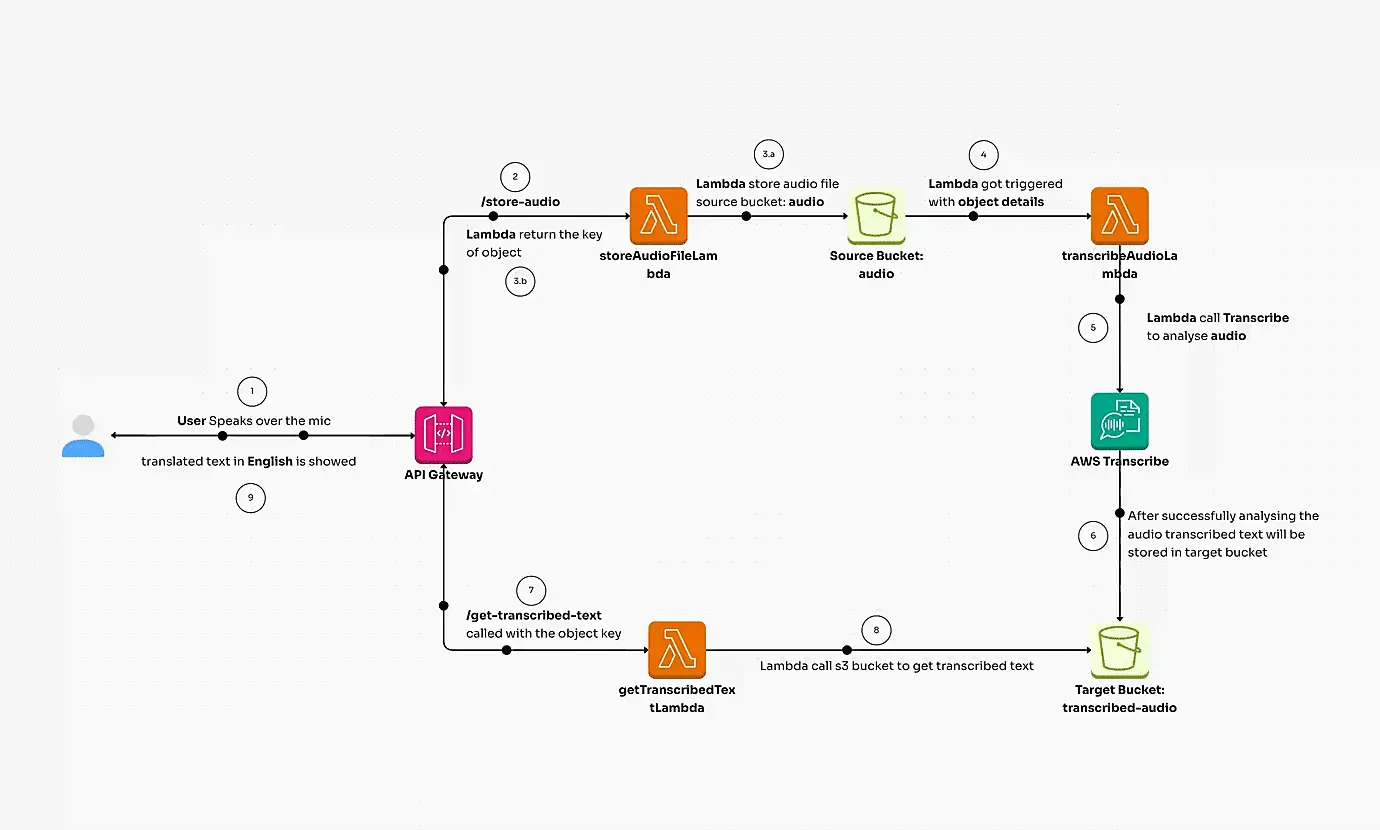
Code Breakdown - Understanding Implementation
Architecture flow consists of three lambdas, storeAudioLambda, transcribeAudioLambda, and getTranscribedTextLambda, and each lambda serves a purpose in the flow. Let’s focus on the first lambda, which is storeAudioLambda:
This lambda function will be invoked as the starting point to store the audio file, along with the metadata (which will be used in transcribeAudioLambda), to store the file lambda, generate the pre-signed URL, and pass it to the user to upload, and transcribeJobName is shared.
// storeAudioFileLambda.js
const { S3Client, PutObjectCommand} = require("@aws-sdk/client-s3");
const { getSignedUrl } = require("@aws-sdk/s3-request-presigner");
const client = new S3Client({ region: "us-east-1" });
/**
* This function is used to generate a pre-signed URL to put an object in s3
* @param {Object} bucketParams - bucketParams contains the bucket name and key of the object you want to put in the bucket
* @returns {String} - returns the presignedUrl to put an object in the bucket
*/
const createPutPresingedUrl = async ( bucketParams ) => {
const putObjectCommand = new PutObjectCommand(bucketParams);
const signedRequest = await getSignedUrl(client, putObjectCommand, { expiresIn: 3600 });
console.log('[INFO] Signed Request:', signedRequest);
return signedRequest;
};
/**
* This handler is used to generate a pre-signed URL to put objects in s3
* @param {Object} event - Event passed to the lambda
* @returns {Object} returns the presigned URL to put object
*/
module.exports.handler = async(event) => {
try {
console.log('[INFO] Event passed to Lambda:', event);
//Key: The key of the object you want to put in the bucket
const { key, targetLanguage } = JSON.parse(event.body);
const transcribeJobName: "translate-job-1", // set this dynamic with user input
const metaData = {
transcribeJobName,
language: targetLanguage
}
const bucketParams = {
Bucket: "audio",
Key: key,
MetaData: metaData
};
// Create a presigned URL to put object in the bucket
const putPresignedUrl = await createPutPresingedUrl(bucketParams);
console.log('[INFO] Put Object Presigned URL:', putPresignedUrl);
return {
headers:{
'Access-Control-Allow-Origin': '*',
'Access-Control-Allow-Methods': '*',
},
statusCode: 200,
body: JSON.stringify({
message: 'Success',
url: putPresignedUrl,
transcribeJobName,
})
};
} catch (error) {
console.log('[ERROR] Error while putting object to s3', error);
throw error;
}
};Once the file is uploaded to the source bucket, transcribeAudioLambda is triggered with the bucket and object info.
- transcribeAudioLambda will extract the bucket name and key from the event records.
- Then, s3 request is made to get the metadata of the object.
- With the metadata info lambda will extract the language and transcribeJobName
- Next, using all the above information transcribeJobParams is prepared and a request to start the transcribe job to AWS Transcribe is made.
- After the job is completed, the transcribed text is stored in the target bucket with the same name as transcribeJobName.
// transcribeAudioLambda.js
const { TranscribeClient, StartTranscriptionJobCommand } = require('@aws-sdk/client-transcribe');
const { S3Client, HeadObjectCommand } = require('@aws-sdk/client-s3');
// Initialize client's
const s3Client = new S3Client({});
const transcribeClient = new TranscribeClient({});
/*
* Calls the s3 bucket to get the metadata of the object
* @params {Object} name - bucket name
* @params {Object} key - bucket key
* @returns {object} returns the bucket metadata
*/
const getMetaData = async (name, key) => {
try {
const metaParams = {
Bucket: name,
Key: key
};
const objectMetadata = await s3Client.send(new HeadObjectCommand(metaParams));
return objectMetadata.Metadata;
} catch (error) {
console.log('[ERROR] Error while getting the metaData', error);
throw error;
}
}
/*
* This function will be triggered after object is successfully uploaded to bucket
* Step1: Extract the bucket name, object key to prepare the audioUri, and mediaFormat
* Step2: get transcribeJobName, language from the bucket metadata
* Step3: prepare the transcribeParams with extracted info, and call AWS Transcribe
* @params {Object} event - event passed to the lambda
* @returns {object} returns the transcribed result
*/
module.exports.handler = async (event) => {
try {
console.log('[INFO] Event passed to Lambda:', event);
const { object:{ key }, bucket:{ name } } = event.Records[0].s3;
const audioUri = `s3://${name}/${key}`;
const mediaFormat = key.split('.')[1]
// get jobName from the metaData
const { transcribeJobName, language } = await getMetaData(name, key);
//Prepare the params for transcribe
const transcribeParams = {
TranscriptionJobName: transcribeJobName,
LanguageCode: language,
Media: { MediaFileUri: audioUri },
MediaFormat: mediaFormat,
OutputBucketName: process.env.TARGET_BUCKET_NAME,
};
// Transcribe: start the transcription job
const transcribeCommand = new StartTranscriptionJobCommand(transcribeParams);
const transcribeResponse = await transcribeClient.send(transcribeCommand);
console.log('[INFO] transcribeResponse from transcribe', transcribeResponse);
return {
statusCode: 200,
body: JSON.stringify({ message: 'Transcription job started', transcribeJobName}),
};
} catch (error) {
console.error('[ERROR] Error while starting transcription job:', error);
throw error;
}
};Once this job is completed, another API request to route “/get-transcribed-text” is made to get the translated text, while making a GET request transcribeJobName is sent in the params so that getTranscribedTextLambda will use this to fetch the transcribed JSON file from the s3 bucket.
// getTranscribedTextLambda
const { S3Client, GetObjectCommand } = require("@aws-sdk/client-s3");
// Create an S3 client
const s3Client = new S3Client({ region: "your-region" });
/**
* Lambda handler to get and convert a JSON object from S3
* @param {Object} event - The event object passed from the API Gateway
* @returns {Object} - The parsed JSON data from the S3 object
*/
module.exports.handler = async (event) => {
try {
console.log('[INFO] Event received:', event);
// Retrieve bucket name and object key from the event
const bucketName = "target-bucket";
const objectKey = event.queryStringParameters.key;
// Prepare the GetObjectCommand parameters
const getObjectParams = {
Bucket: bucketName,
Key: objectKey,
};
// Fetch the object from S3
const command = new GetObjectCommand(getObjectParams);
const response = await s3Client.send(command);
//TODO: Convert the S3 object file to a normal json
const translatedTextObject = translateFile(response.body)
console.log("[INFO] Retrieved and parsed JSON data:", translatedTextObject);
return {
statusCode: 200,
headers: {
"Access-Control-Allow-Origin": "*",
"Access-Control-Allow-Methods": "*",
},
body: JSON.stringify(translatedTextObject),
};
} catch (error) {
console.error("[ERROR] Failed to get object from S3:", error);
return {
statusCode: 500,
body: JSON.stringify({ error: "Failed to retrieve and parse S3 object" }),
};
}
};
IAM Permission
As Lambda’ is performing different operations, it’s important to provide the required permission to lambda, which allows them to invoke s3 and AWS Transcribe.
storeAudioFileLambda permission:
- Lambda requires permission to store objects in the source bucket.
{
"Version": "2012-10-17",
"Statements": [
{
"Effect": "Allow",
"Action": [
"s3:PutObject"
],
"Resource": [
"arn:s3:::audio/*"
]
}
]
}
transcribeAudioLambda permission:
- Lambda requires permission to be triggered from the s3 bucket.
- Lambda requires permission to call objects to get metadata.
- Lambda requires permission to invoke AWS Transcribe for the translation job.
{
"Version": "2012-10-17",
"Statements": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject",
"s3:PutObject"
],
"Resource": [
"arn:s3:::audio/*"
]
},
{
"Effect": "Allow",
"Action": [
"transcribe:GetTranscriptionJob",
"transcribe:StartTranscriptionJob"
],
"Resource": "*"
}
]
}getTranscribedTextLambda permission:
- Lambda requires permission to get s3 object.
{
"Version": "2012-10-17",
"Statements": [
{
"Effect": "Allow",
"Action": [
"s3:GetObject"
],
"Resource": [
"arn:s3:::transcribed-audio/*"
]
}
]
}
Conclusion
Following all the above steps, we now have a greater understanding of how we can approach building a text-to-text translator and speech-to-text apps using AWS Services, leveraging AWS Translate and AWS Transcribe. By following the steps we not only built the application but also gained an understanding of the importance of AI in the current market, and the breakdown of the User and Back-end perspective with the required code and IAM to implement while building a simple application, by the end you could have your own translator app.
Reference
- AWS Translate
- AWS Transcribe - knowing the service



%20(1).svg)

.svg)








.webp)