

Introduction
CloudGTO is a platform that simplifies the development process and speeds up the creation of Minimum Viable Products (MVPs) for developers. It offers infrastructure-as-code templates, pre-configured application code, monitoring capabilities, authorization mechanisms, and least-privilege IAM permissions for various services. This significantly reduces the time and effort required to create a functional MVP.
With CloudGTO, developers can concentrate on their core application logic and unique features, instead of being slowed down by repetitive and time-consuming tasks. With its comprehensive set of tools and resources, CloudGTO helps developers quickly iterate and refine their ideas, speeding up time-to-market and promoting innovation. Whether you’re an experienced developer or a beginner, CloudGTO provides a powerful toolkit to streamline your development process and easily bring your ideas to life.
What to Expect From This Post
In this article, we will:
- Explore the recently released CloudGTO GraphQL use case with the DynamoDB Single Data Source Blueprint
- Customize the DynamoDB Single Data Source Blueprint for a Recipe app
- Deploy our CloudGTO Recipe app to AWS
- Test our app with GraphBolt
Prerequisites
To follow this tutorial, you must have the following:
- An AWS Account and a user with administrative privileges to deploy AWS AppSync, CloudWatch, X-ray, Lambda, S3, Cognito, DynamoDB
- Serverless Framework (version 3 is recommended)
- AWS CLI installed and set up on your local computer with the Access Key ID and Secret Access Key of your IAM user with Admin privilege
- A CloudGTO account which you can sign up for by visiting app.cloudgto.com
- GraphBolt if you wish to follow along with the tests but you could still use the AWS AppSync Console.
Some CloudGTO concepts
CloudGTO is built around Use Cases and Blueprints. For example, the REST API Use Case helps you build a serverless REST API with Blueprints. Blueprints help in automatically generating IaC templates around the most common serverless REST API architectures. The Blueprints are deployable and testable. The CloudGTO UI experience exposes you to a few form fields to provide information about your project and some basic configuration parameters of the resources that you would like to include in it. In a nutshell, Blueprints are a group of AWS services that are already preconfigured with a few editable form fields which you can either use directly or modify according to your project.
To speed up the development of our Recipe GraphQL API, we will use the newly released GraphQL Use Case and the Dynamo (Single Data Source) Blueprint.
Building the Recipe GraphQL API
The Recipe API is a simple GraphQL API that will provide users with a single endpoint to perform CRUD operations on the Recipe database. To build the API with CloudGTO, we will use the “DynamoDB (Single Data Source)” Blueprint.
This Blueprint is architected with the following AWS services:
Amazon Cognito
Amazon Cognito is a fully managed identity and access management (IAM) service that helps you securely manage user identities in your web and mobile applications. Cognito provides a hosted user directory, as well as authentication, authorization, and user management features.
AWS AppSync
AWS AppSync is a fully managed GraphQL service that helps you build scalable, secure, and high-performance APIs. AppSync makes it easy to connect your data from multiple sources, including Amazon DynamoDB, Amazon Aurora, and AWS Lambda, and expose it through a GraphQL API.
Amazon DynamoDB
Amazon DynamoDB is a fully managed, serverless, key-value NoSQL database that is designed to run high-performance applications at any scale. DynamoDB offers built-in security, continuous backups, automated Multi-Region replication, in-memory caching, and data import & export tools.
In a nutshell, the DynamoDB (Single Data Source) Blueprint will provide us with a managed Customer IAM, GraphQL server, and NoSQL database. All these services are serverless so there are no servers to provision or maintain and no operating systems and software to patch and update. Let’s have a quick look at our simple data model.
Our Data Model
Let’s assume that for a quick start, we have the 'Recipe' and 'User' entities in our data model. The other entities depend on other factors that are not immediately in our control for now but we need to get something up and running. This is achievable with minimal effort with a platform like CloudGTO.
The data model for the Recipe App will have the following entities:
- 'Recipe': A recipe is a set of instructions for preparing a dish. Each recipe has a title, description, image URL, ingredients, steps, cooking time, serving size, difficulty, cuisine, course, rating, and reviews.
- Other entities could include 'User', 'Ingredient', 'Category', 'Rating', or 'Review' but for simplicity’s sake, we will those out of this tutorial.
Since we are using Amazon Cognito for user management, we won’t have a dedicated database table for Users.
Primary Key Structure
We will use a simple primary key of 'id'
Attributes
The Recipe entity will have the following attributes:
- id (partition key)
- difficulty
- authorId
- title
- description
- preparationTime
- cookingTime
- instructions
- imageUrl
- createdAt
Access Patterns
Here are some access patterns to start with:
- Create a Recipe by ID
- Get Recipe by ID
- Update Recipe by ID
- Delete Recipe by ID
- List Recipes
Step 1: Service Creation
After you log into your CloudGTO account, click on the “BUILD SERVICE” button to start the process which will take you to the Service Definition page.

On the Service Definition page, we will input our service name and a short description.
The REST API Use Case is selected by default. Click on the drop-down arrow and select GraphQL API. This will automatically select the DynamoDB (Single Data Source) blueprint for us.
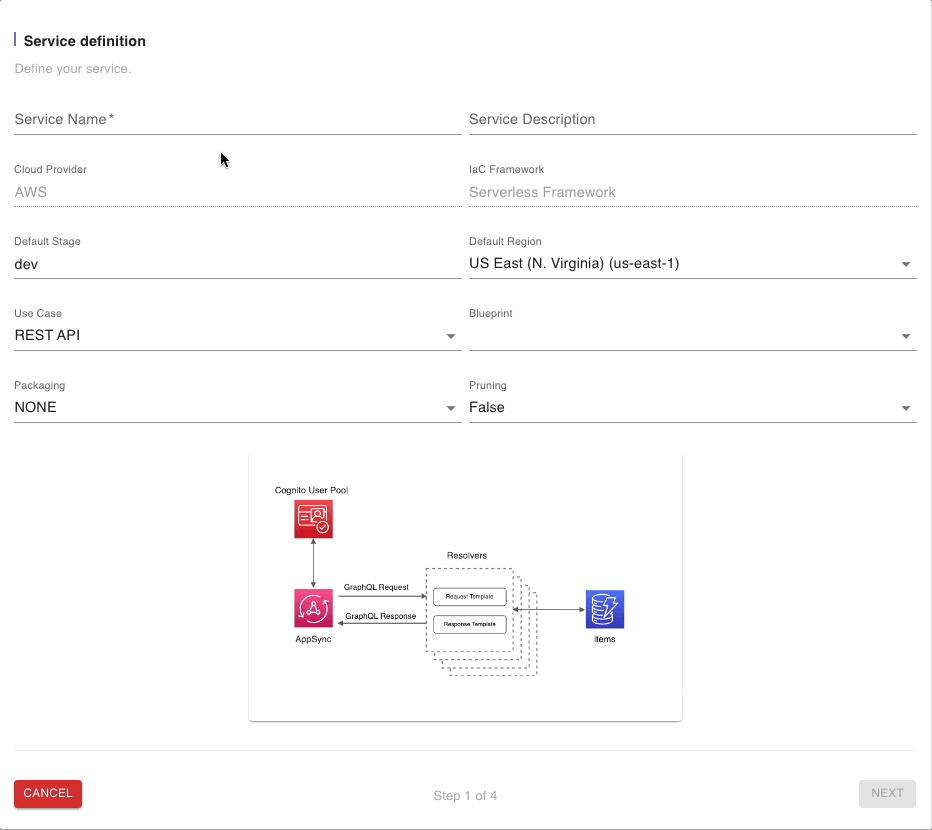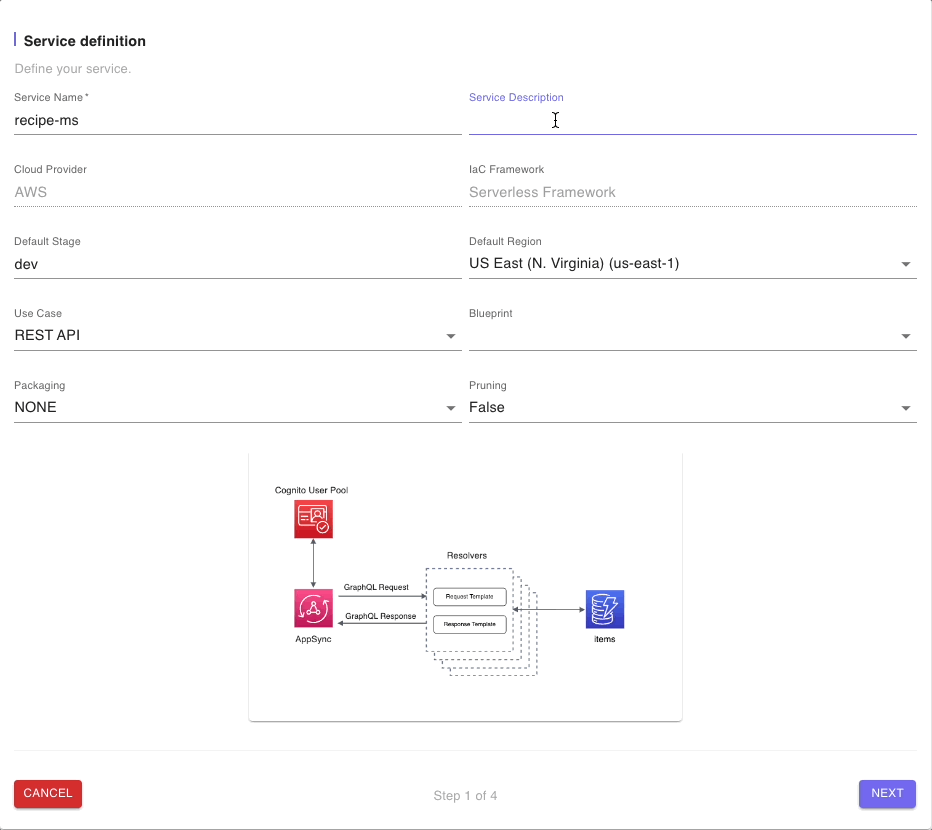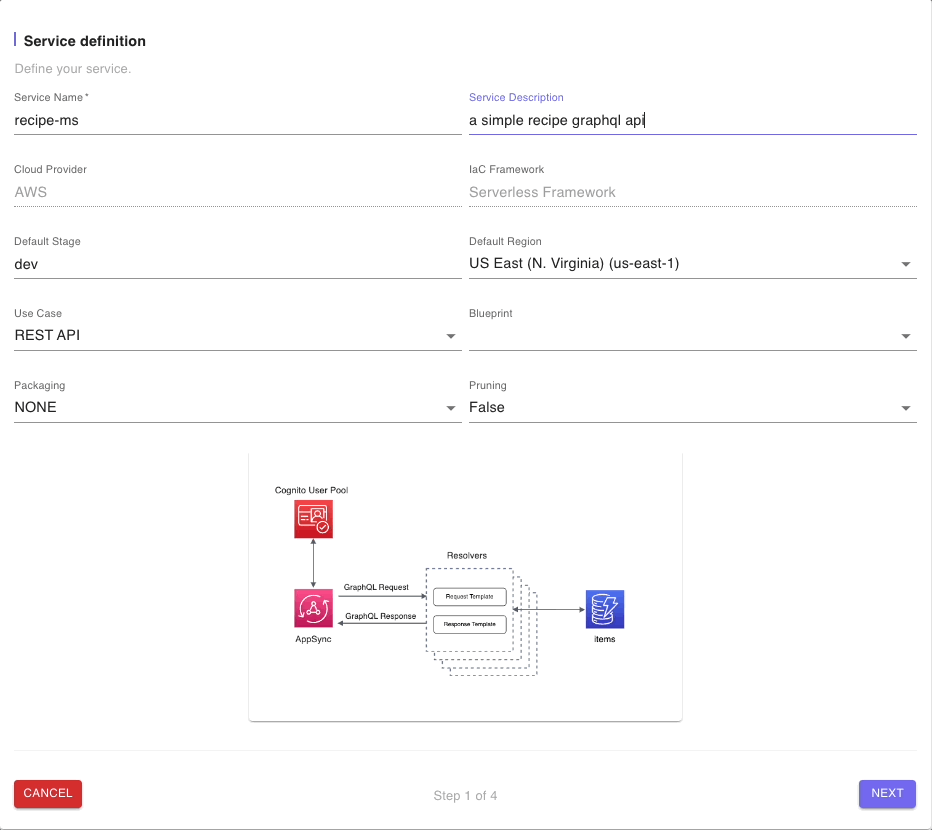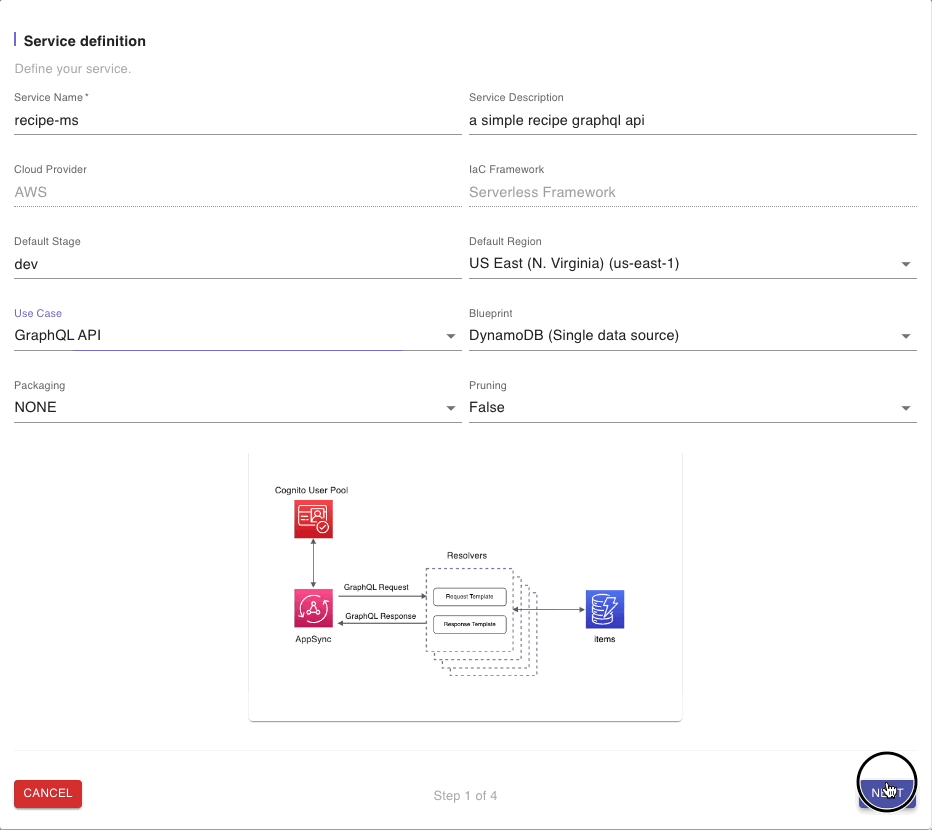
Take note of the architectural illustration which highlights the use of a single DynamoDB table. We will leave the defaults in the other fields and click on “NEXT” to go to the next step.
Step 2: AppSync API Details
In this step we will provide a name to the AWS AppSync managed resource. We will leave the other defaults such as Cognito for Auth and click on “Next”.
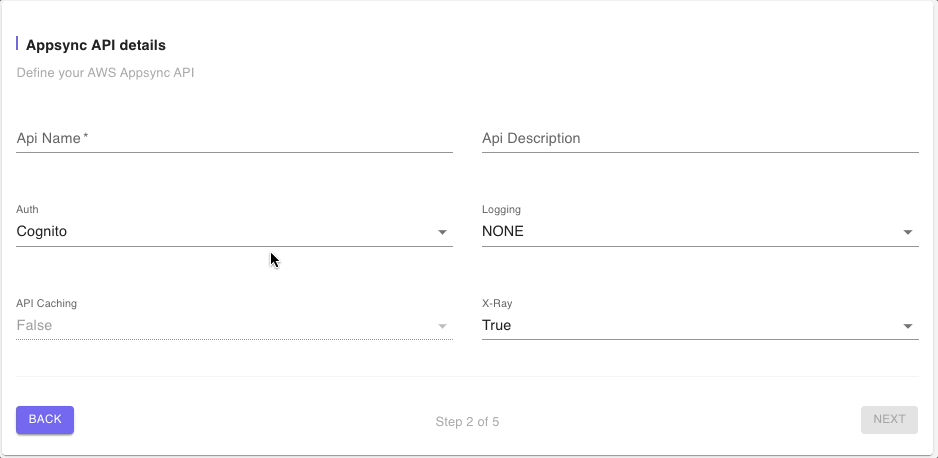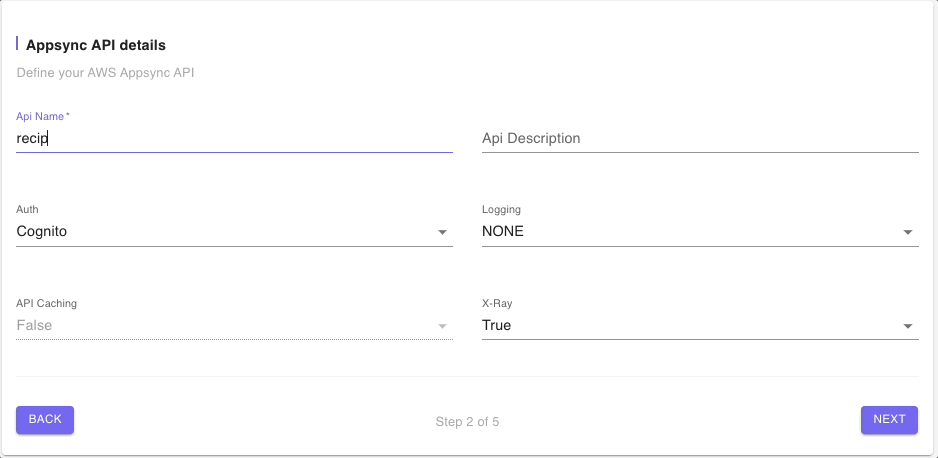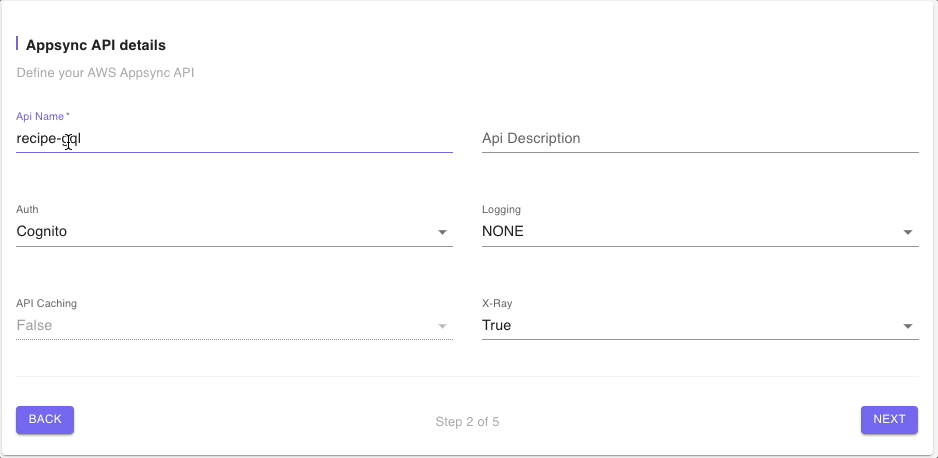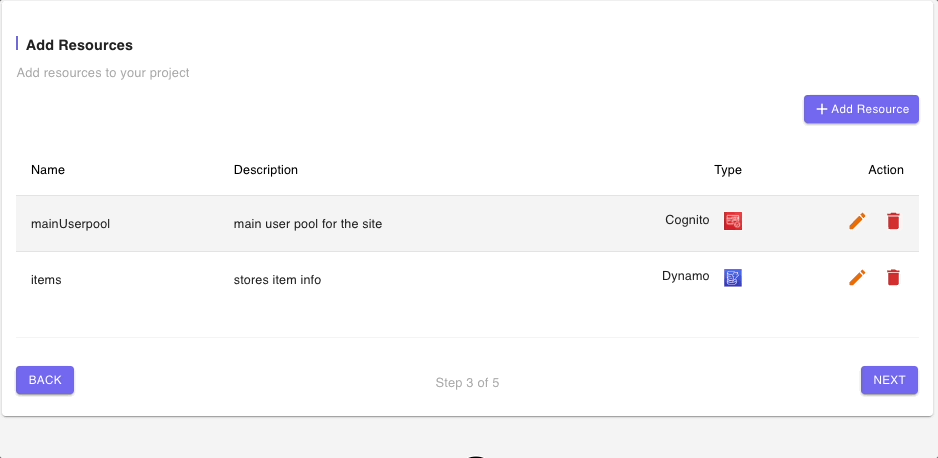
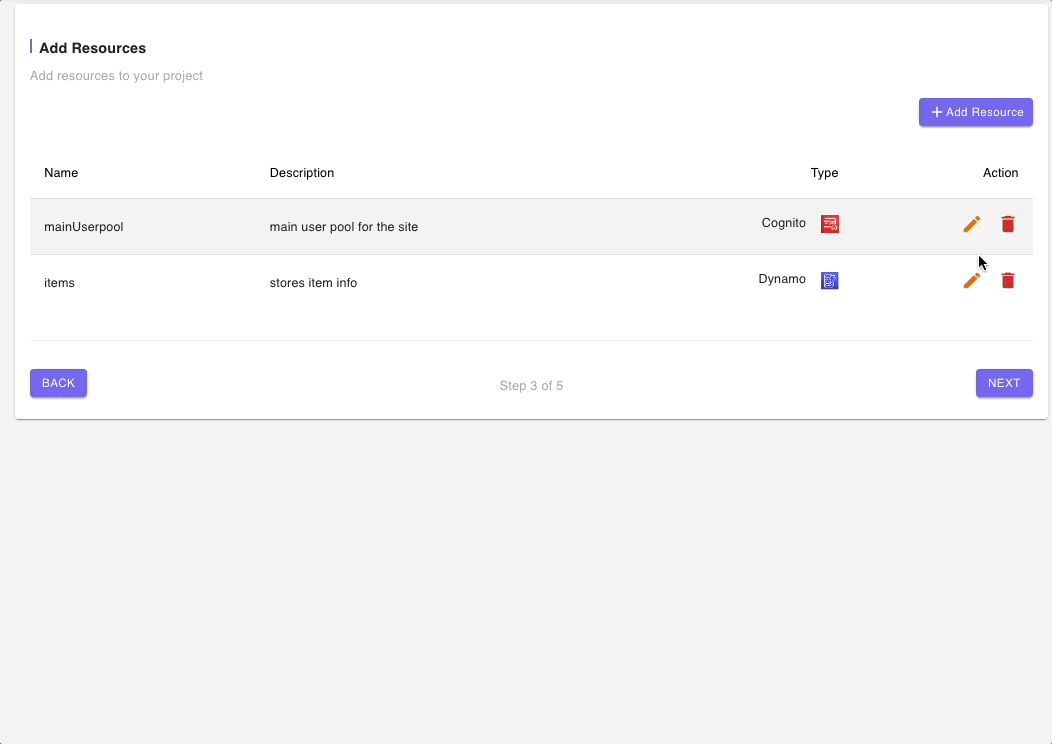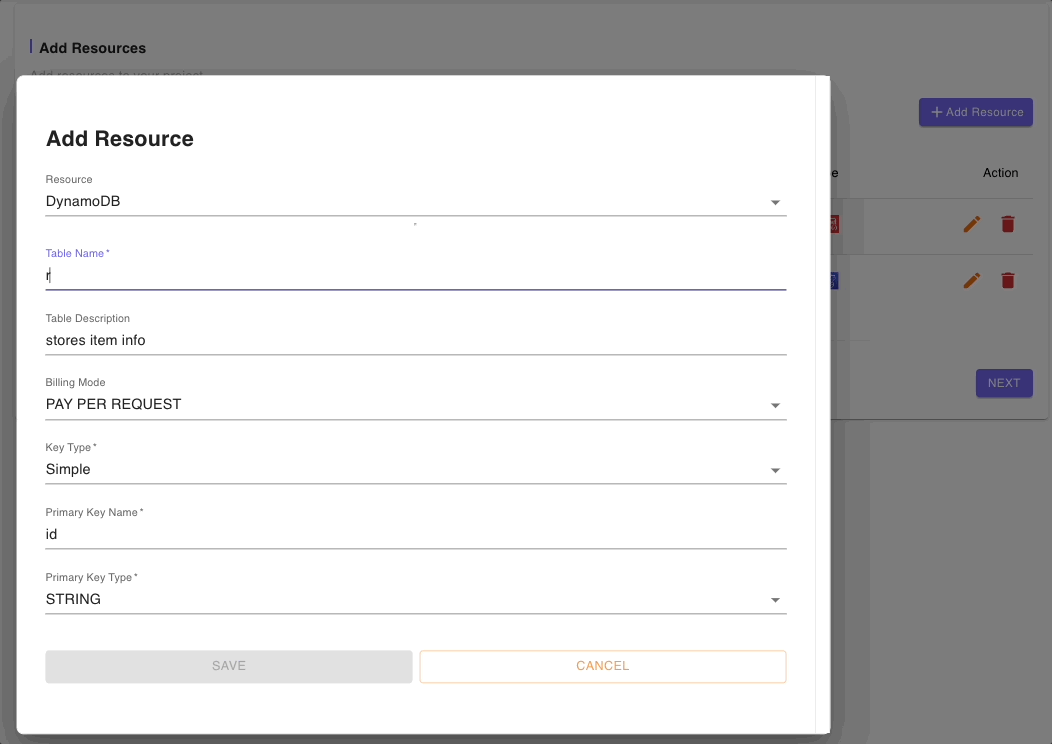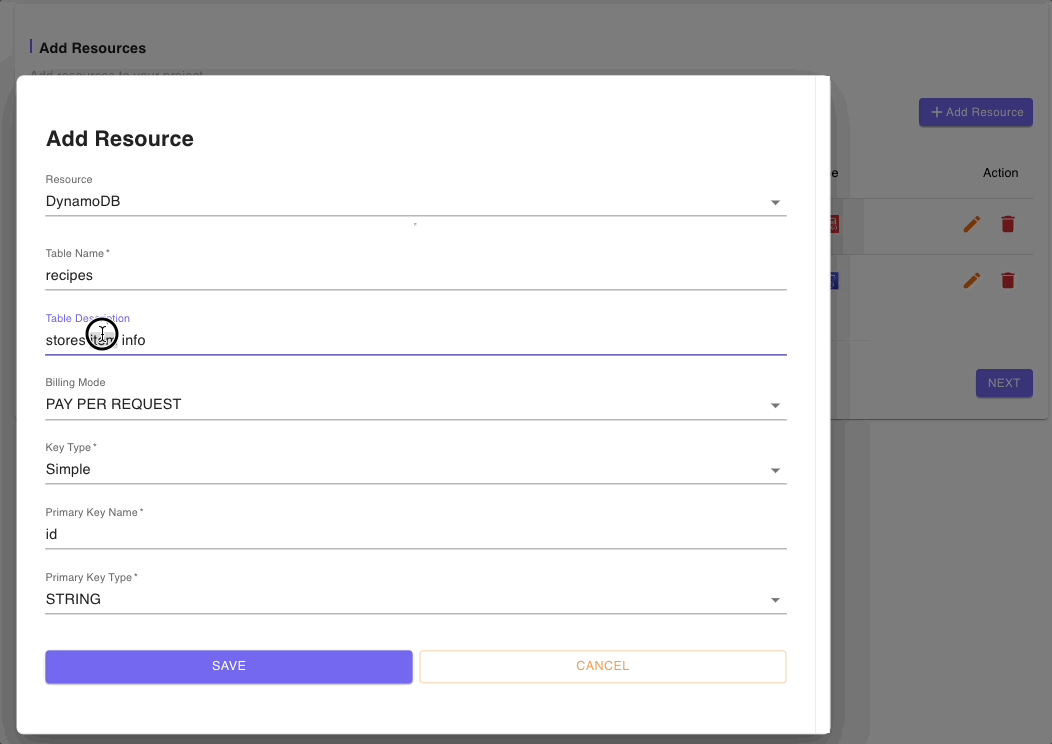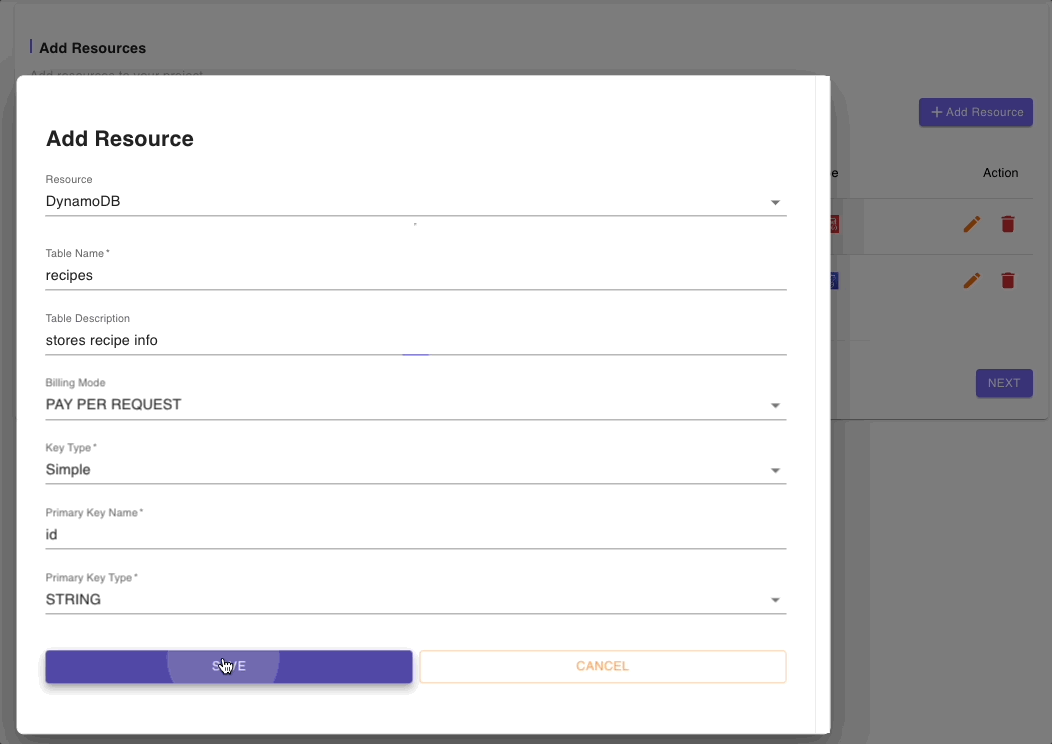
Step 3: Add Resources
The DynamoDB (Single Data Source) Blueprint also provides some boilerplate code for a Cognito user pool. The Cognito resource defaults will suffice for our Recipe app but we will need to update the generic fields in the DynamoDB resource to reflect our use case.
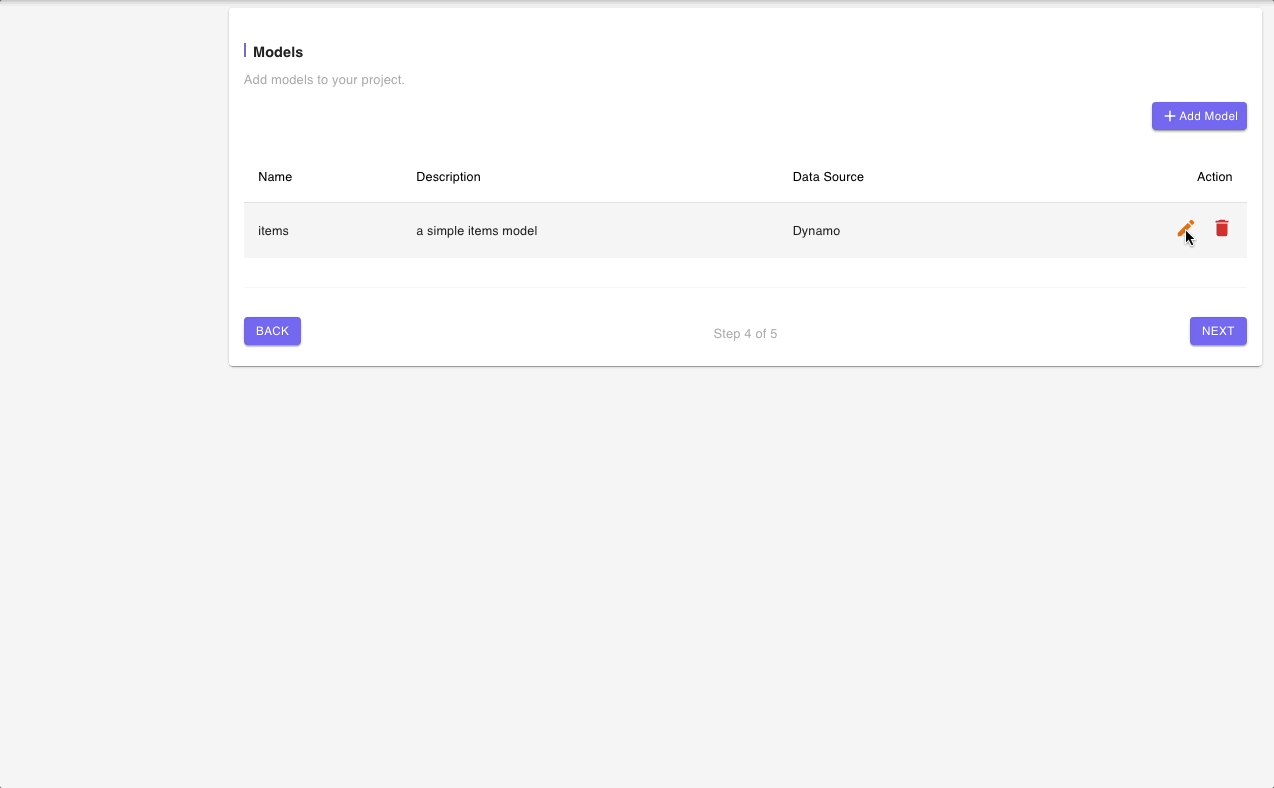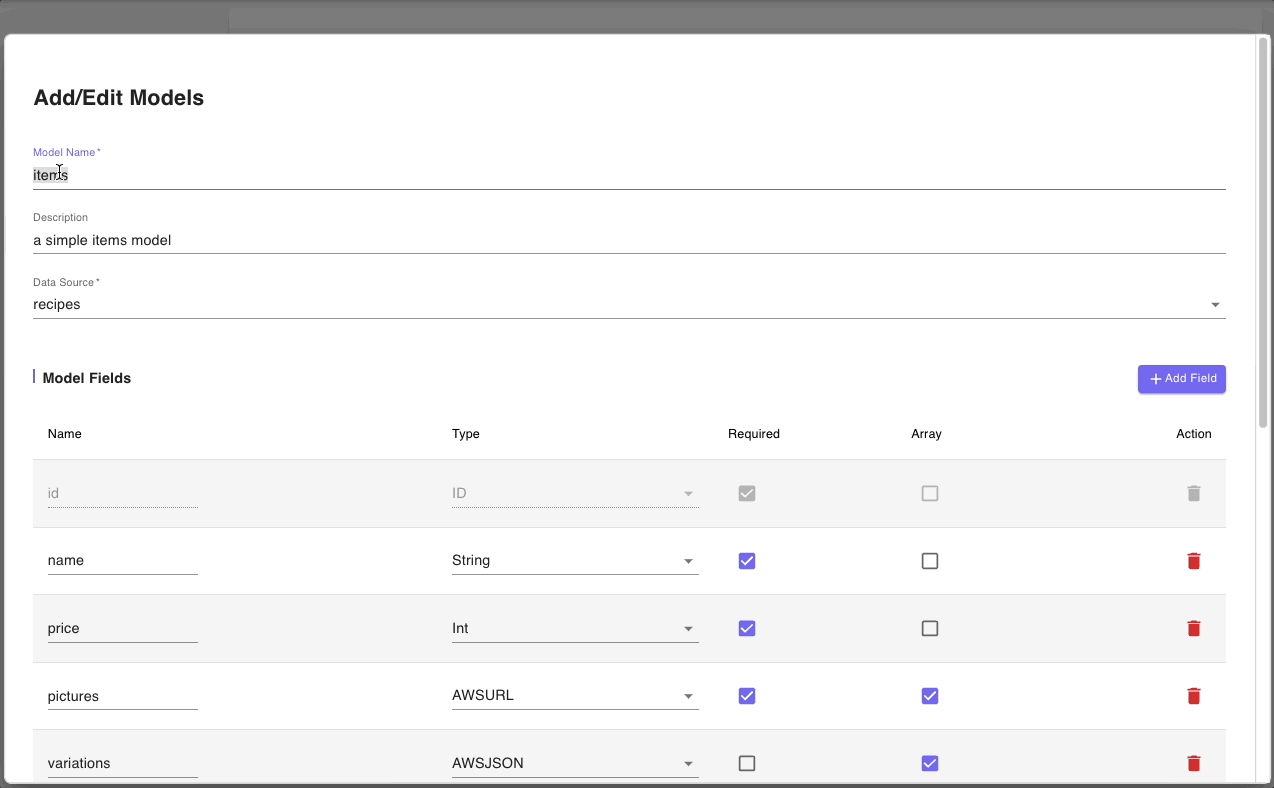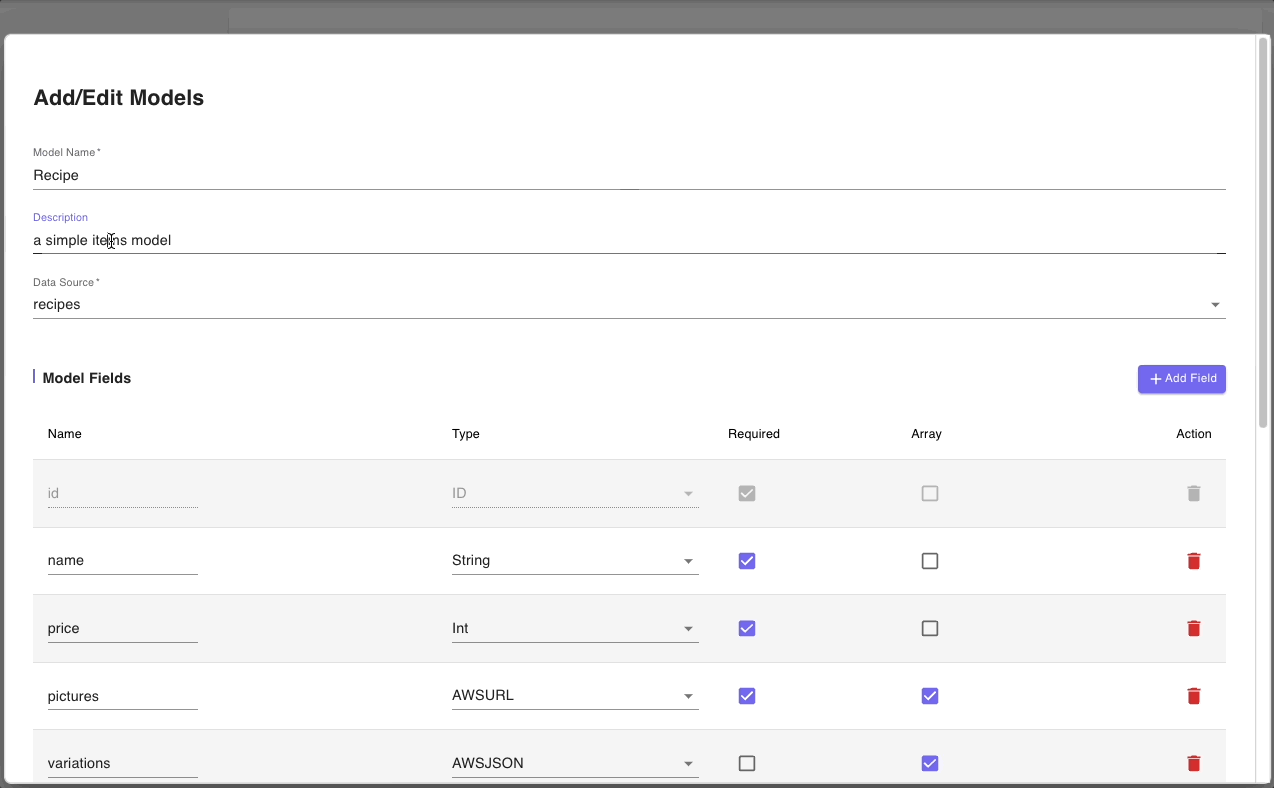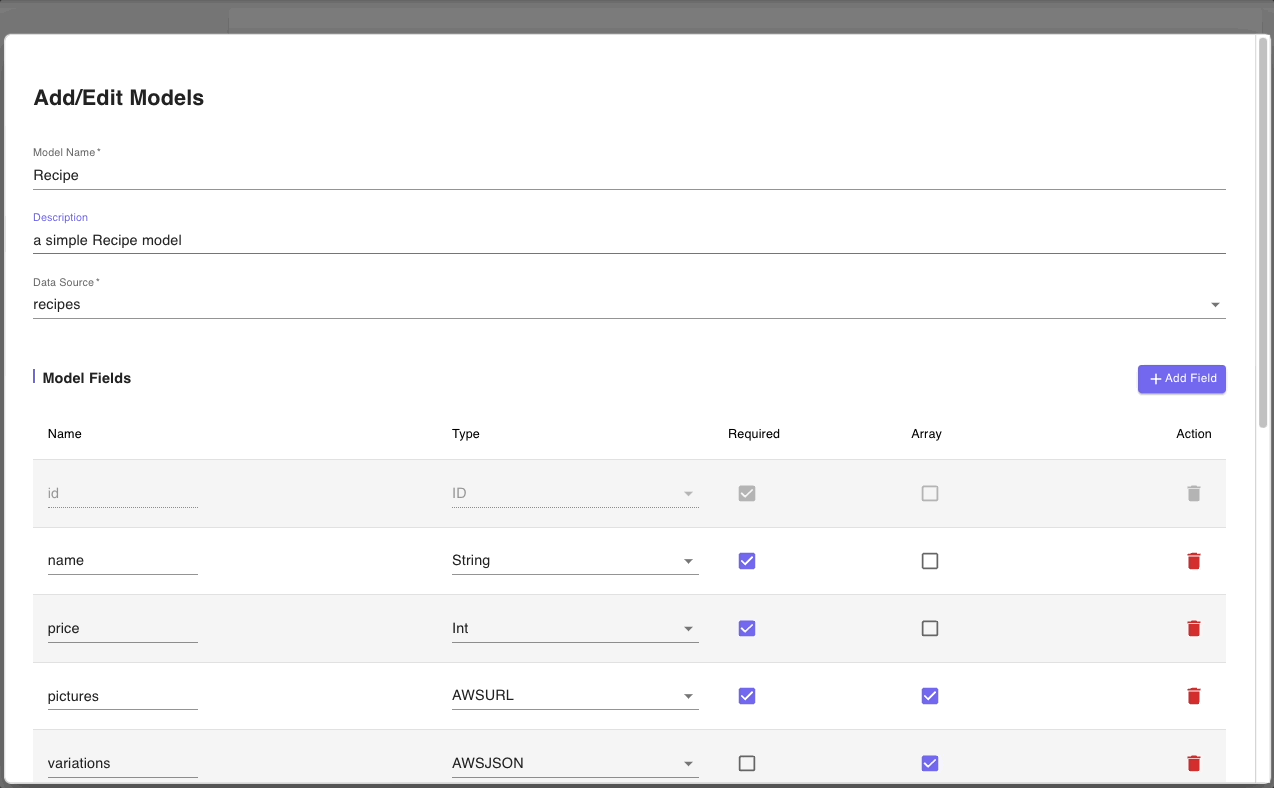
Step 4: Models
Just as in the previous step, there is already a default 'Items' model that comes with the Blueprint. We will need to update the default Model with the information for our Recipe App.

Let’s start with the general information about the model. Notice that the Data Source is 'recipes' which reflects the changes we made in the previous step. So now, we just need to change the Model Name and Description.
Next, we will update the Model fields section with the attributes from our data model.

The last section is for the Resolvers which we will equally update four Recipe App.
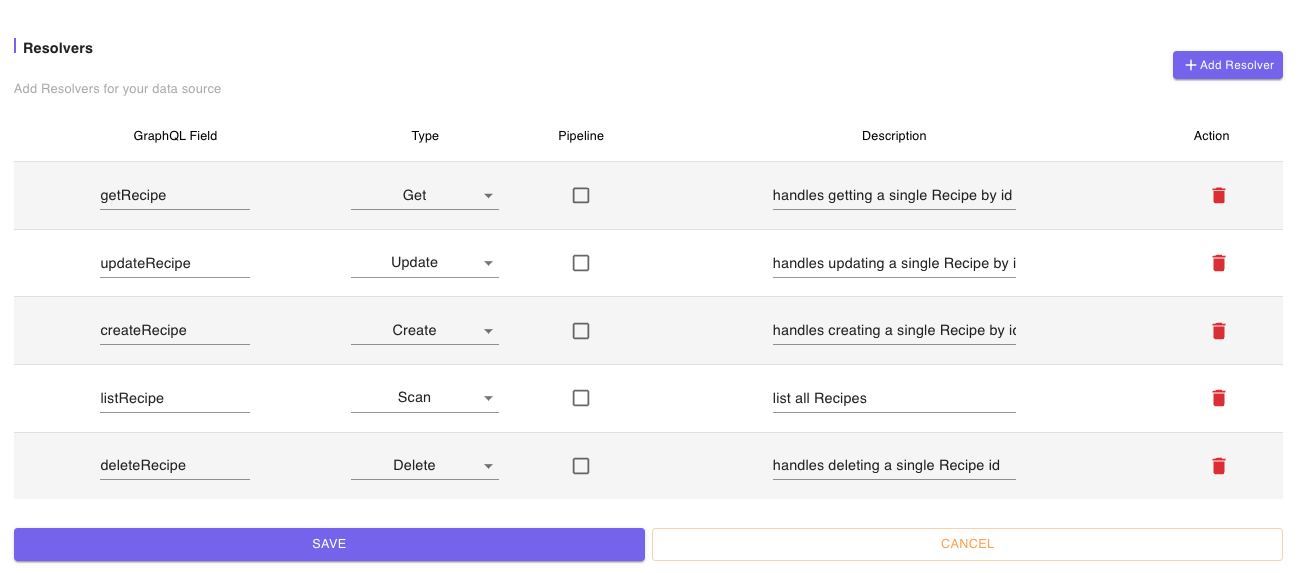
After saving we will return to the Models summary page.

Click on “NEXT” to continue to the Summary page
Step 5: Summary
Next, we have the Summary of all the resources we have defined in the previous steps which we are ok with. There are deployment notes at the end which we will use when deploying to AWS.
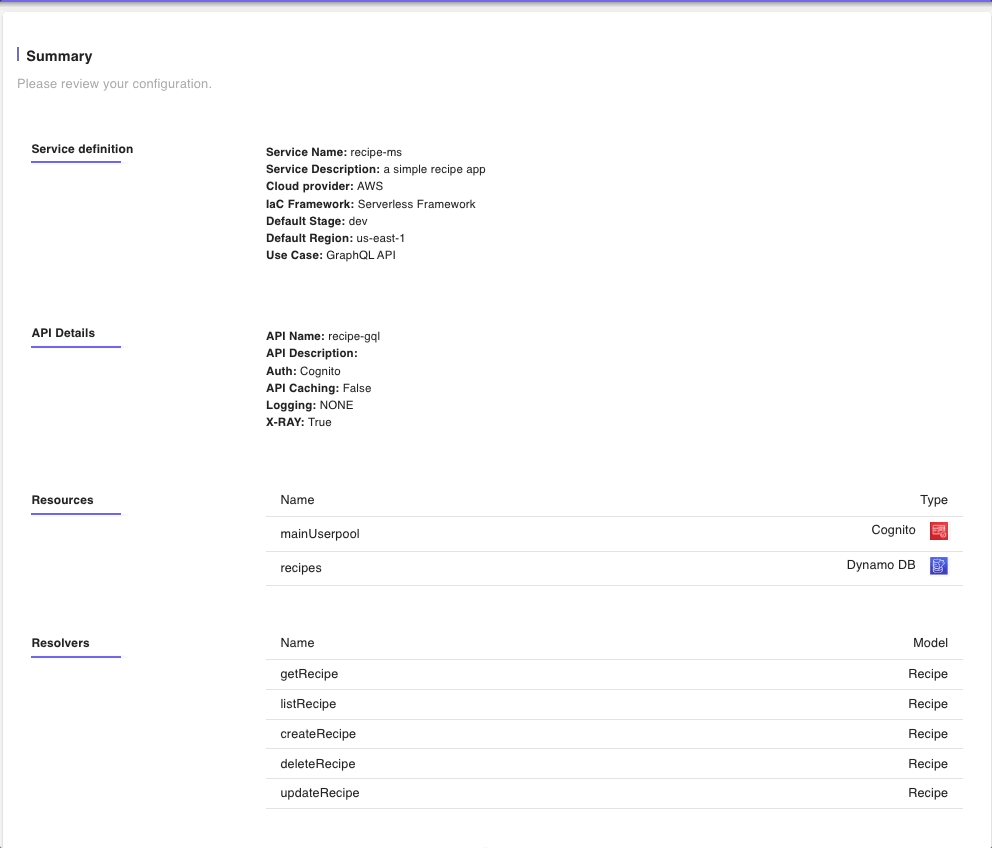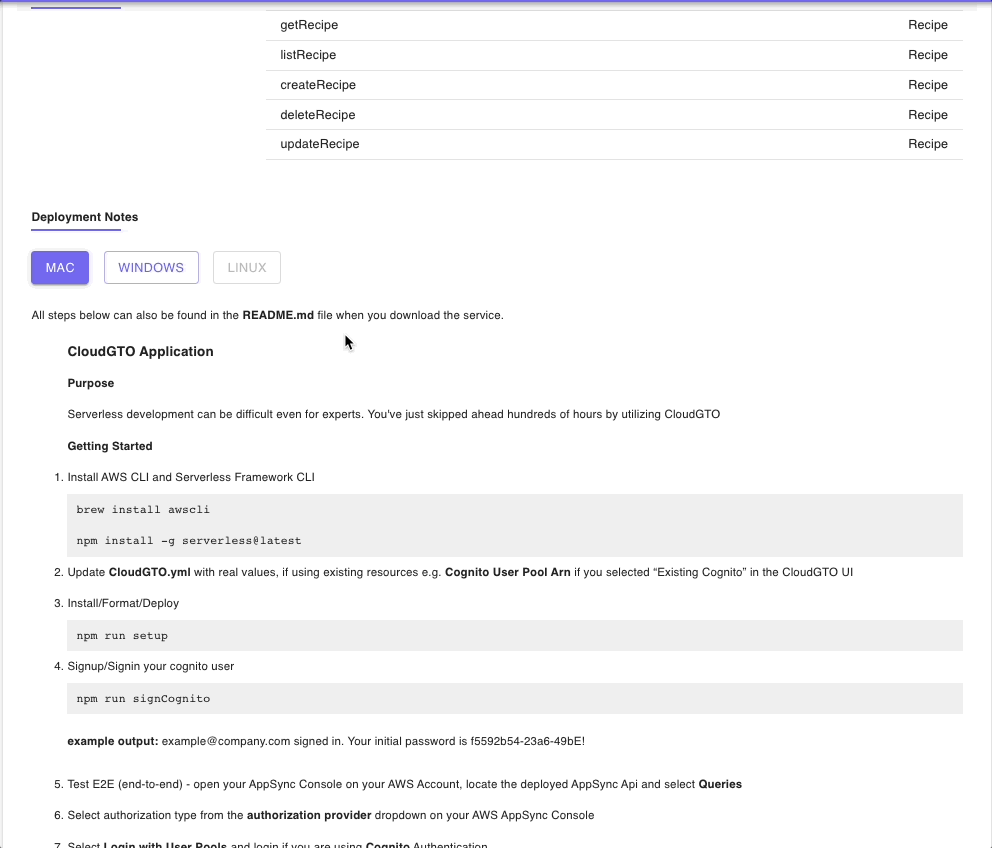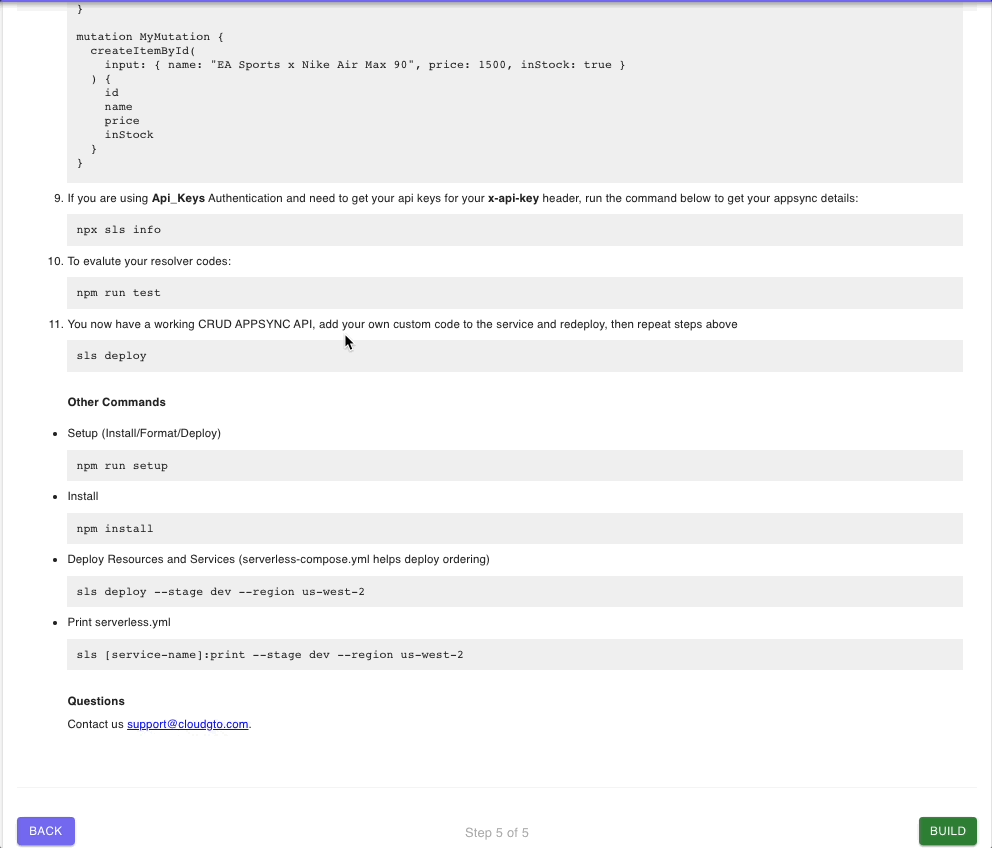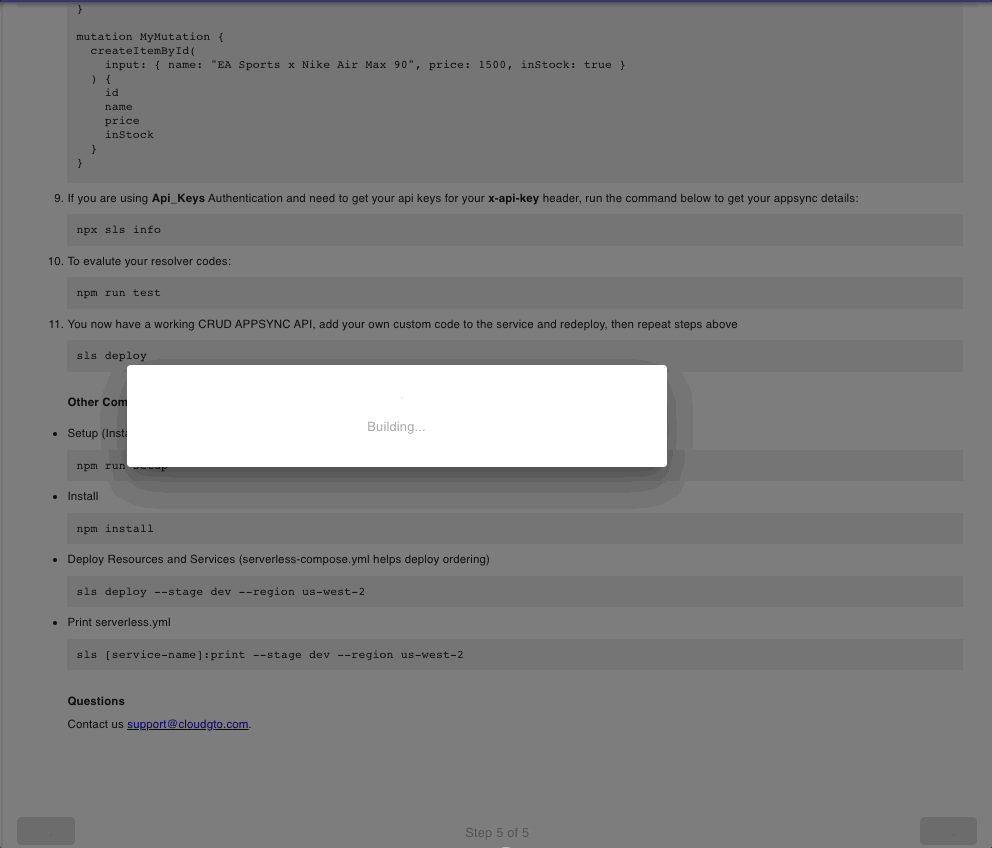
Click on “BUILD” to start building the project files.
Step 6: Download the project
After a few seconds, the build process generates all the IaC and application code files with all of the information we provided. We can also see an infrastructure diagram of what would be deployed.
We will click on the download button to download the project zip file named serverless.zip. Then rename it and open it up in VSCode for further development.
Step 6: Deployment
After unzipping the download project zip file, the first thing to do is to have a look at the README file which has information about the project as well as some scripts to automate the deployment to AWS.
If you already have the AWS CLI and Serverless Framework installed, the first command to run is 'npm run setup' which will install our packages and deploy our project to AWS
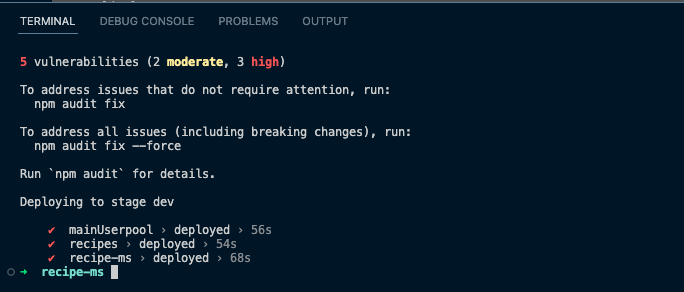
Heading over to the AWS Console, we can see the resources have been deployed successfully. In CloudFormation, we can see all the stacks for our project were successfully deployed
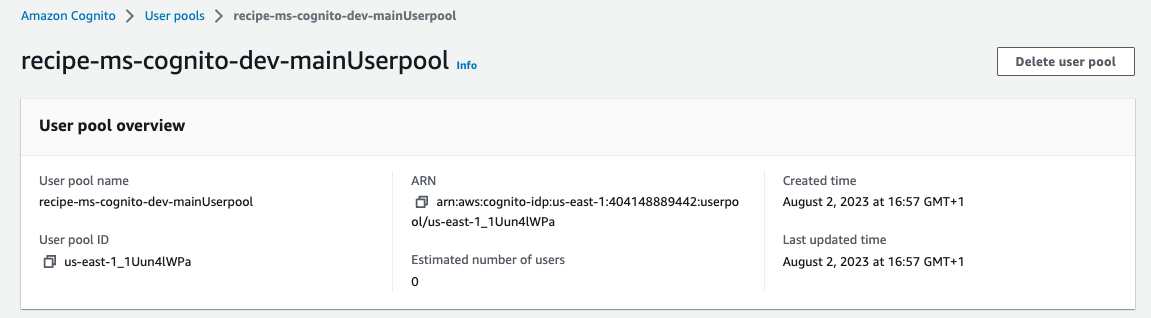
We have our Amazon Cognito User Pool:
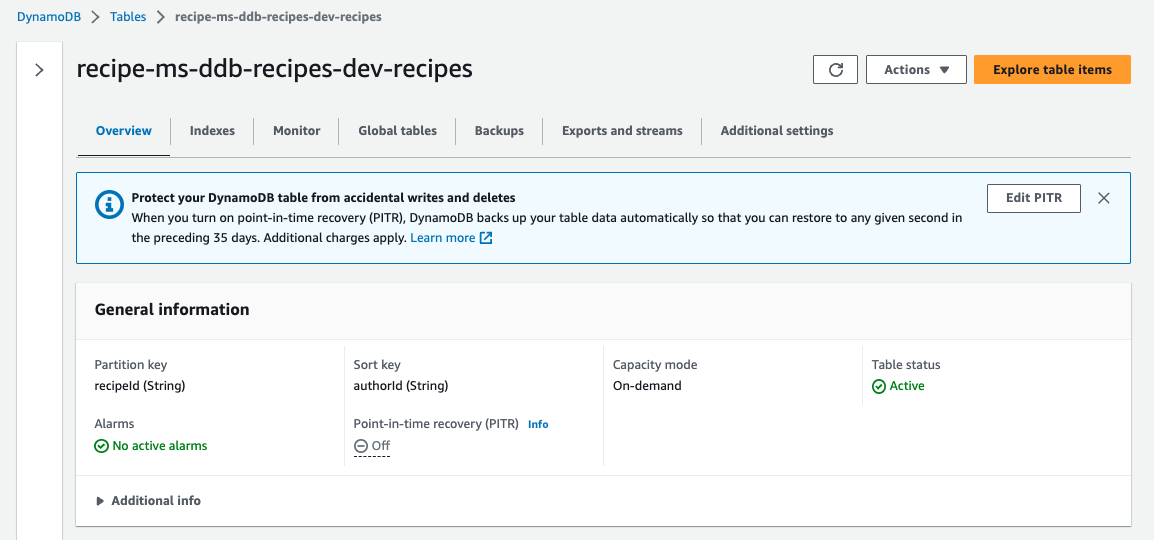
We have our Amazon DynamoDB Table:
And we have our AWS AppSync API:

Step 8: End-to-end tests with GraphBolt
Since our API requires an API Key and Amazon Cognito Authorization, we will need to pass those in our header for each API call. Fortunately for us, there are helper scripts in the README.md file that can help us obtain those easily.
First, we will execute the 'npm run signcognito' script to get our API key

You can also run the 'npx sls info' script to get information about the project

Setting up GraphBolt
GraphBolt is a desktop tool that helps you develop, test, debug, and manage your AWS AppSync APIs. I like GraphBolt because it automatically uses your AWS CLI profiles to pull all the information relevant to your AppSync API’s without requiring you to open multiple pages on the AWS Console.
It is currently in public beta and is free at the time of this post. The free version will suffice for our preliminary tests.
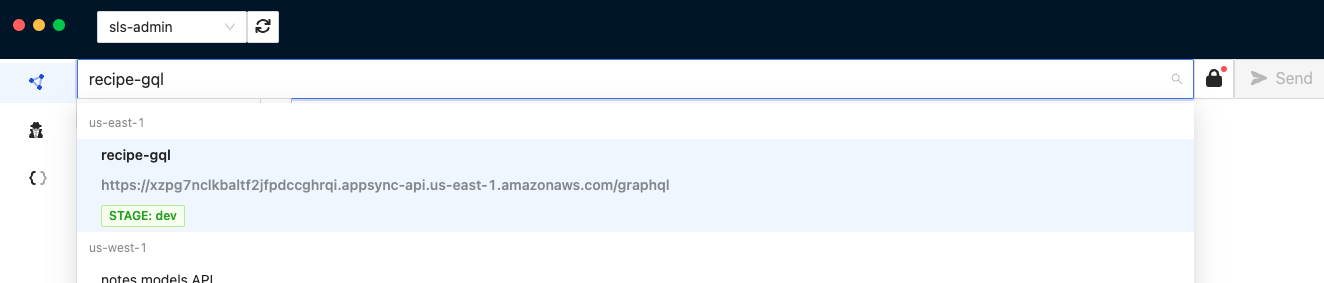
We will launch the GraphBolt app which is already installed on your computer and click on the address bar to select our recipe-gql API which it has automatically pulled from my AWS account.
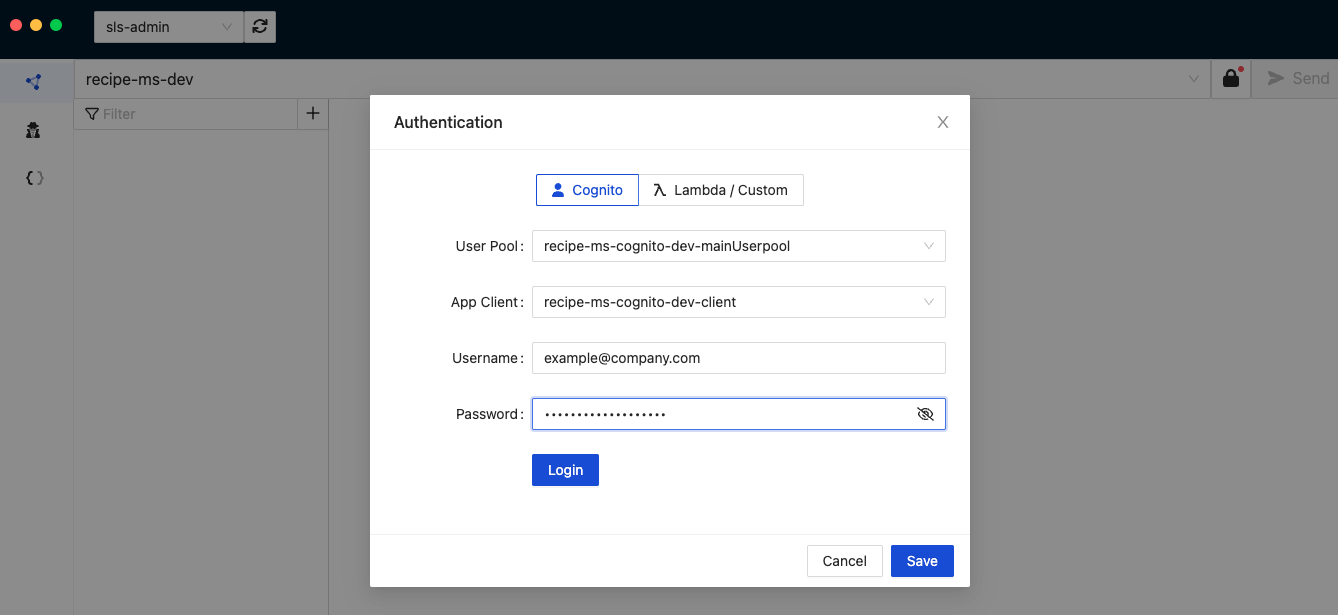
Next, we will click on the padlock icon on the right of the address bar which will display an Authentication modal. The User Pool and App Client will automatically be selected since these are the only ones available for our API. All we need to do is enter the Cognito username and password which we obtained previously with the 'npm signCognito' script.
Now we are ready to test our resolvers. For demonstrative purposes, we are going to do the following tests:
- Create a Recipe by ID
- Get Recipe by Author (User) ID
- Update Recipe by Author (User) ID
- List Recipes
- Delete Recipe by Author (User) ID
'CreateRecipe'
We are going to create 2 recipes using the following mutations:
Here is how we create a CreateRecipe Operation in GraphBolt:
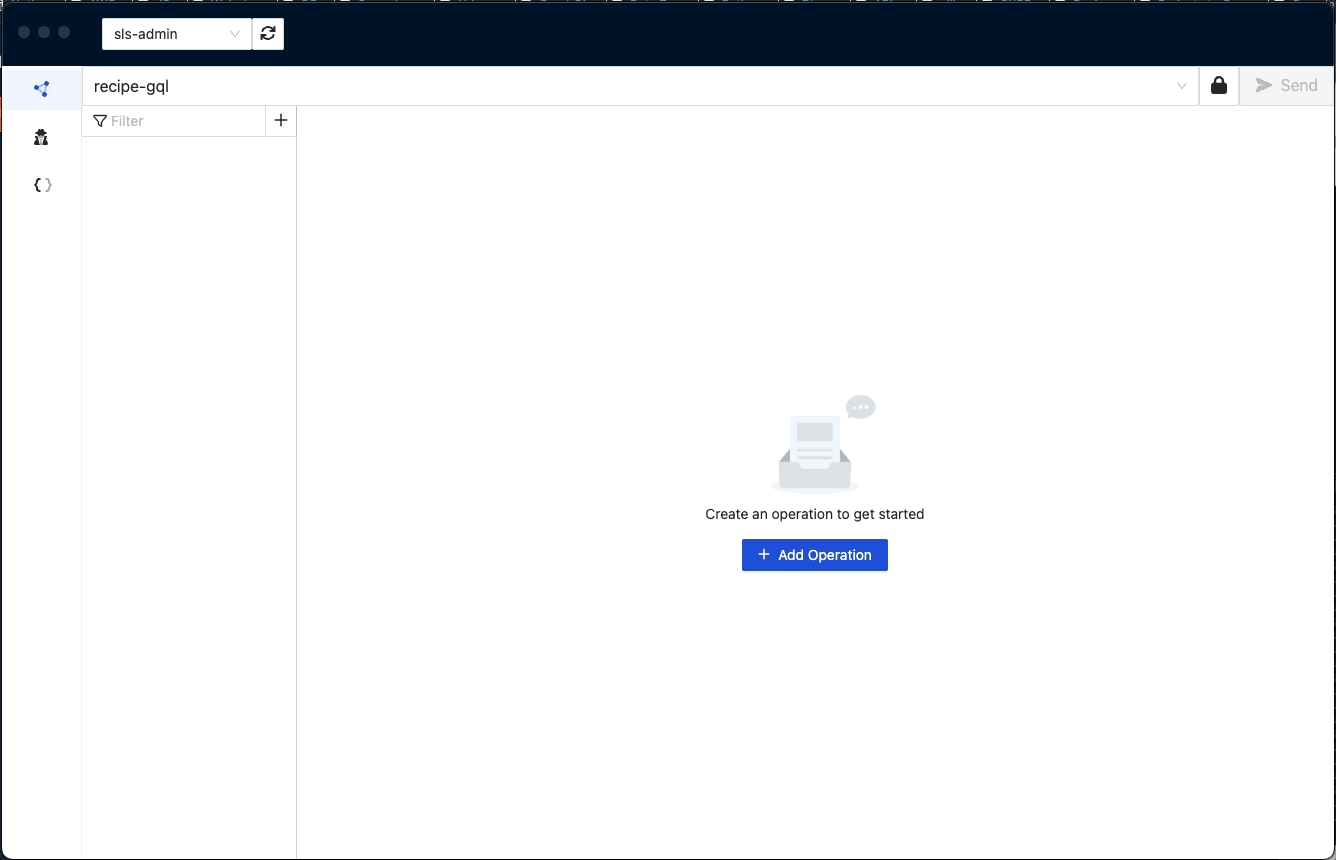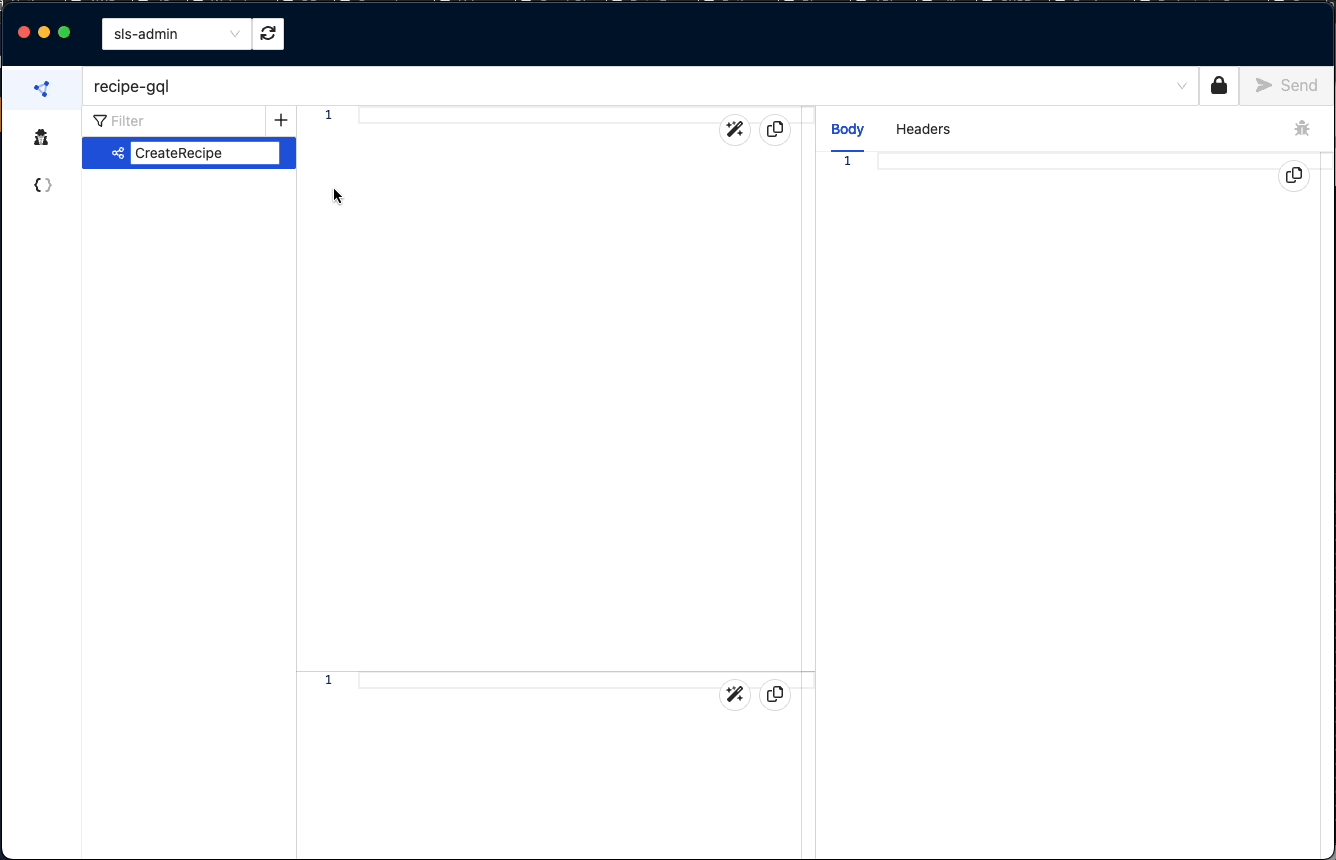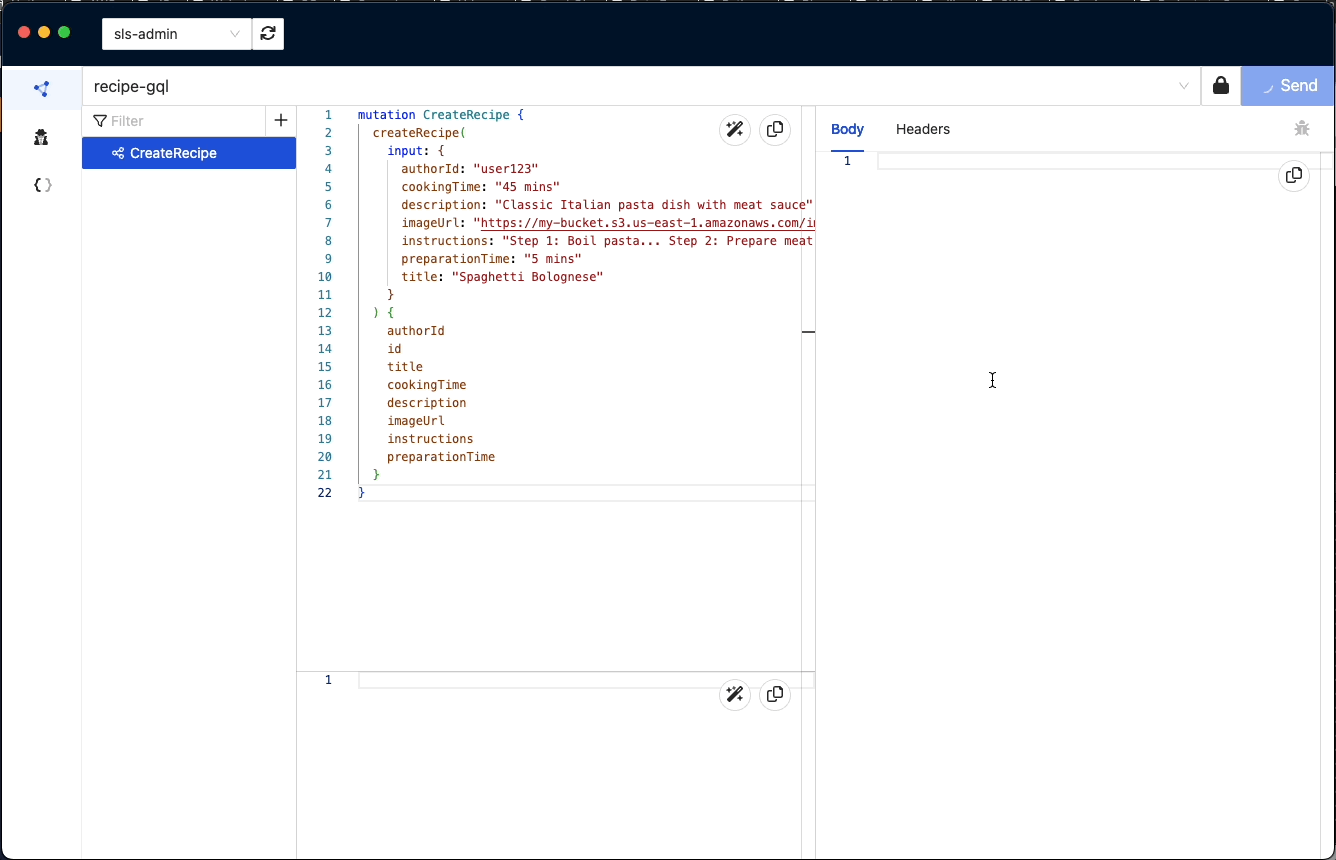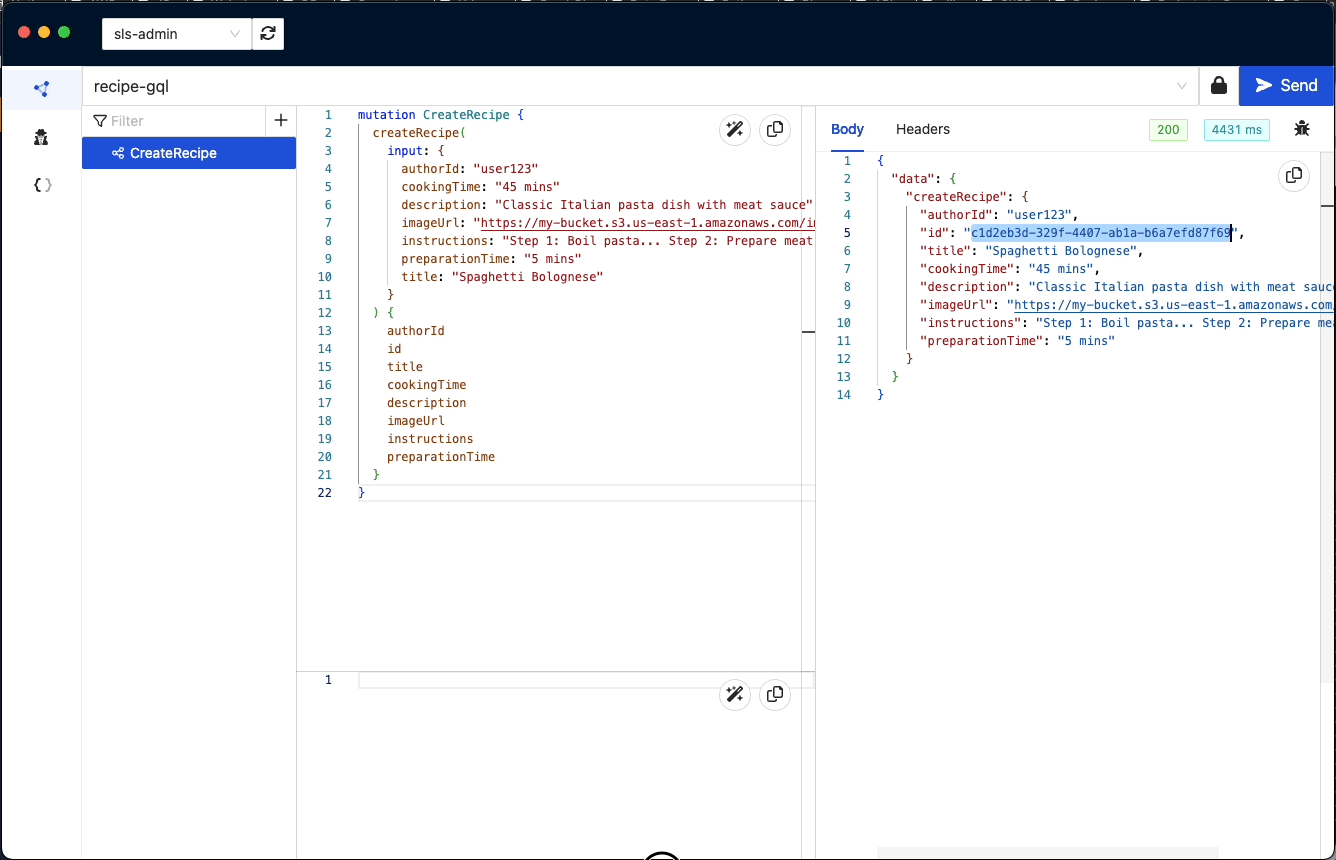
We will use the returned ids for the next operations: '"id": "c1d2eb3d-329f-4407-ab1a-b6a7efd87f69"' & '"id": "9d8f66fb-79a8-49d9-a24c-9f2412892ad4"'
'GetRecipe'
We will use the ids to get the Recipes we just created.
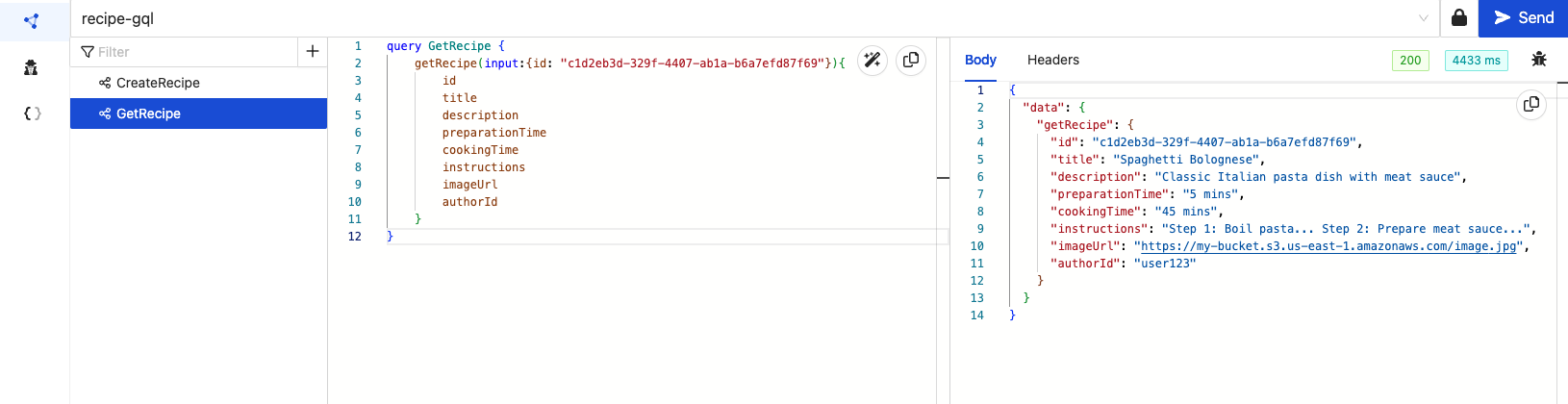
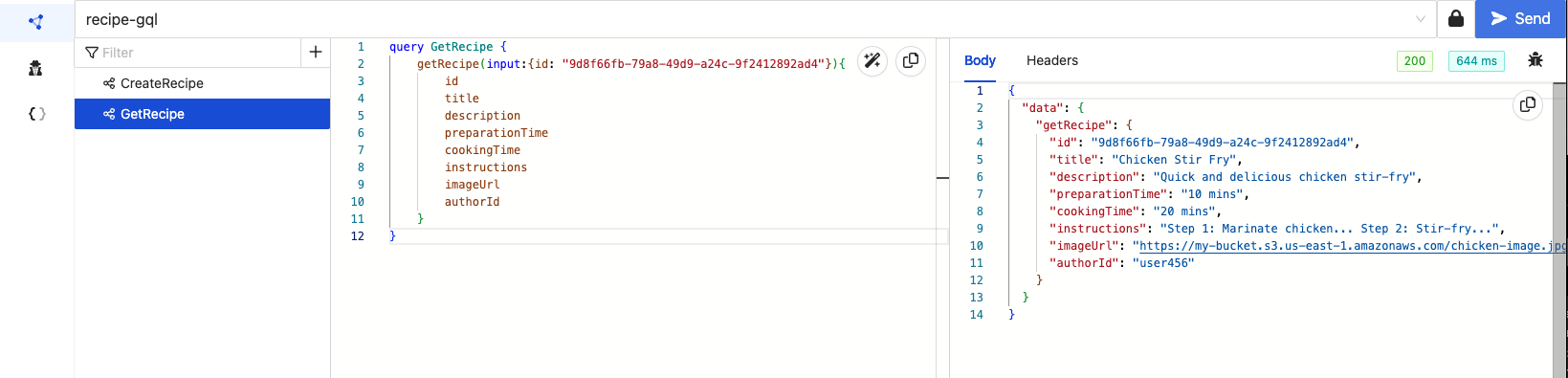
'UpdateRecipe'
We will use the UpdateRecipe mutation to update the Stir-Fry Chicken recipe
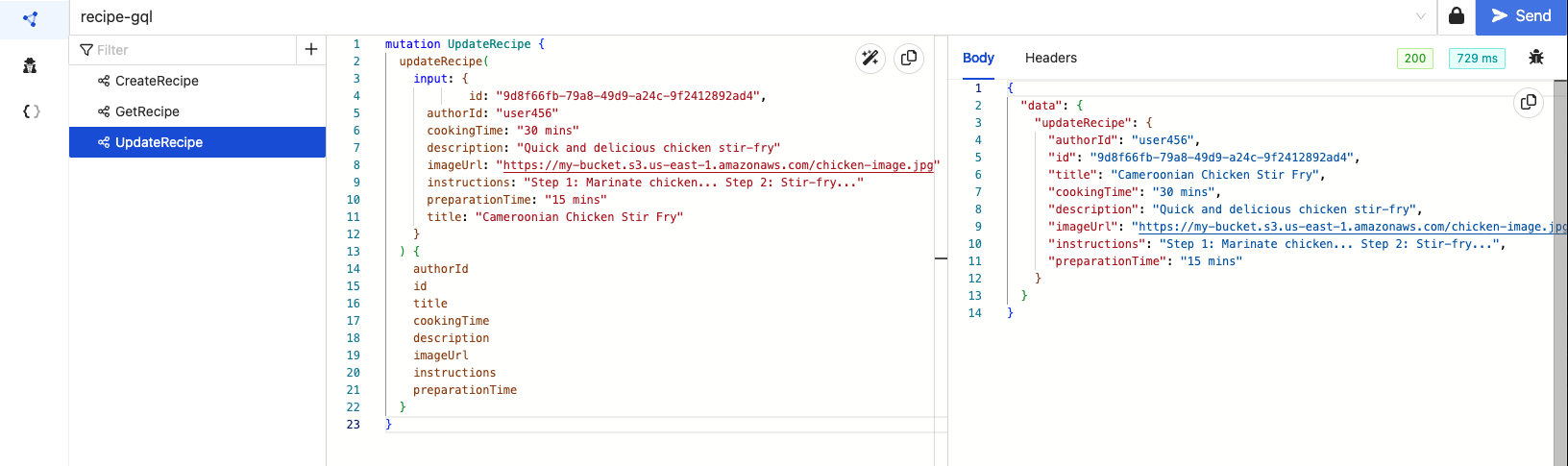
'ListRecipe'
Let's see all the recipes we have created so far:
We can see the two recipes we created in the results.
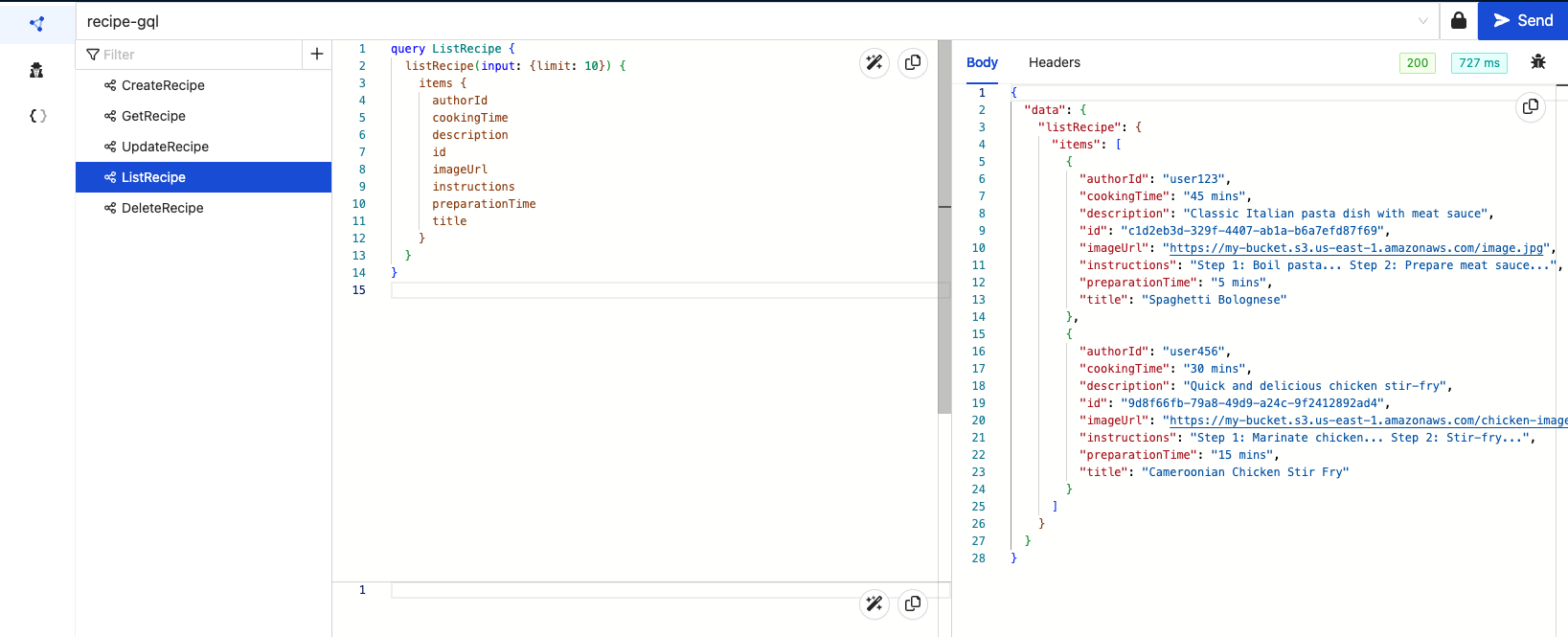
'DeleteRecipe'
Let’s try deleting one of the recipes using the 'id' :

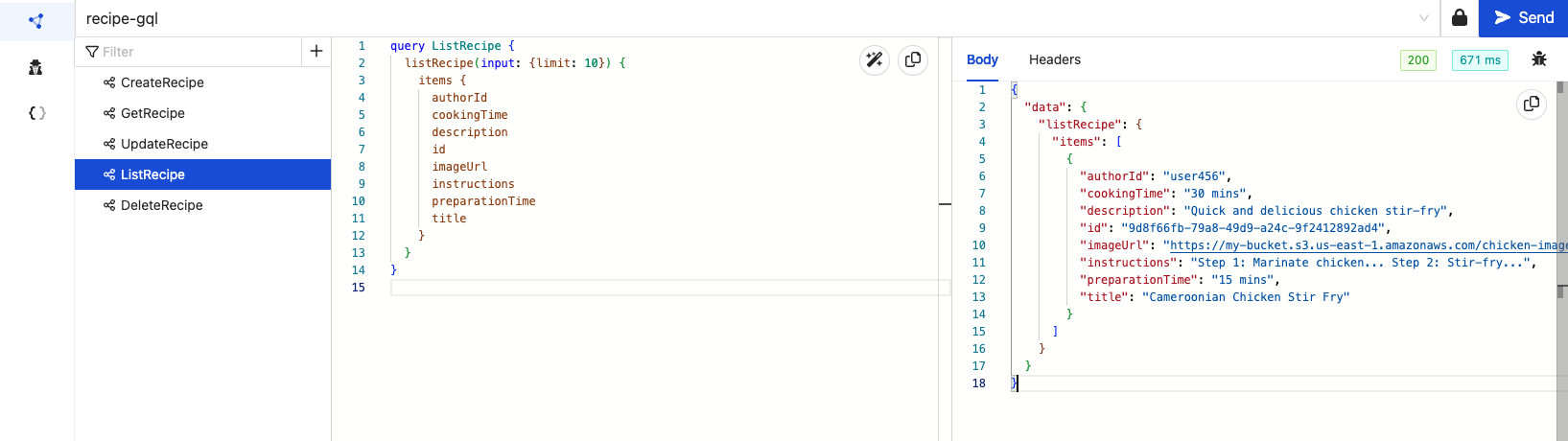
To confirm that the recipe was deleted, we will run the 'ListRecipe' operation again and confirm that only a single recipe is left.
Conclusion
We had the opportunity to dive into the newly introduced CloudGTO GraphQL use case through the DynamoDB Single Data Source Blueprint. Not only did we explore its capabilities, but we also took the initiative to tailor the DynamoDB Single Data Source Blueprint to suit the requirements of a Recipe API. The culmination of our efforts led us to successfully deploy our CloudGTO Recipe App API on AWS.
To ensure the efficiency and accuracy of our GraphQL operations, we leveraged GraphBolt—an intuitive desktop tool designed to simplify the testing of AWS AppSync APIs. This enabled us to validate our API's functionality and performance with ease.
It's worth noting that CloudGTO is currently available in public beta, offering you the chance to explore its functionalities at no cost. You can experience it firsthand by visiting cloudgto.com. The development of new features is an ongoing process, driven by feedback and insights from the community. If you're keen on seeing more use cases, we encourage you to contribute your feedback and help shape the evolution of CloudGTO.



%20(1).svg)

.svg)









.webp)