

Introduction
CloudGTO is a platform that simplifies the development lifecycle and speeds up the creation of Minimum Viable Products (MVPs) for developers. It offers infrastructure-as-code templates, pre-configured application code, monitoring capabilities, authorization mechanisms, and least-privilege IAM permissions for various services. This significantly reduces the time and effort required to create a functional MVP.
With CloudGTO, developers can concentrate on their core application logic and unique features, instead of being slowed down by repetitive and time-consuming tasks. With its comprehensive set of tools and resources, CloudGTO helps developers quickly iterate and refine their ideas, speeding up time-to-market and promoting innovation. Whether you’re an experienced developer or a beginner, CloudGTO provides a powerful toolkit to streamline your development process and easily bring your ideas to life.
What to Expect From This Post
In this article, we will:
- Explore the recently released CloudGTO GraphQL use case with the DynamoDB Multiple Data Sources Blueprint
- Build and deploy the Blueprint to AWS
- Testing the Blueprint with GraphBolt
Prerequisites
To follow this tutorial, you must have the following:
- An AWS Account and a user with administrative privileges to deploy AWS AppSync, CloudWatch, X-ray, Lambda, S3, Cognito, DynamoDB
- Serverless Framework (version 3 is recommended)
- AWS CLI installed and set up on your local computer with the Access Key ID and Secret Access Key of your IAM user with Admin privilege
- A CloudGTO account which you can sign up for by visiting app.cloudgto.com
- GraphBolt if you wish to follow along with the tests but you can still use the AWS AppSync Console.
Some CloudGTO concepts
CloudGTO is built around Use Cases and Blueprints. For example, the REST API Use Case helps you build a serverless REST API with Blueprints. Blueprints help in automatically generating IaC templates around the most common Serverless REST API architectures. The Blueprints are deployable and testable. The CloudGTO UI experience exposes a few forms to provide information about your project and some basic configuration parameters of the resources that you would like to include in it. In a nutshell, Blueprints are a group of AWS services that are already preconfigured with a few editable form fields which you can either use directly or modify according to your project requirements.
DynamoDB Multiple Data Sources Blueprint
The Multiple Data Sources Blueprint is based on a data model typically used by blogging apps. It is also used at least in part by social media platforms, discussion forums, product review websites, etc. Generally, any application that allows users to create and interact with content can use this type of data model.
Before going into the details of the Blueprint’s data model, let’s list out the main AWS services that the Blueprint will build for us:
Amazon Cognito
Amazon Cognito is a fully managed identity and access management (IAM) service that helps you securely manage user identities in your web and mobile applications. Cognito provides a hosted user directory, as well as authentication, authorization, and user management features.
AWS AppSync
AWS AppSync is a fully managed GraphQL service that helps you build scalable, secure, and high-performance APIs. AppSync makes it easy to connect your data from multiple sources, including Amazon DynamoDB, Amazon Aurora, and AWS Lambda, and expose it through a GraphQL API.
Amazon DynamoDB
Amazon DynamoDB is a fully managed, serverless, key-value NoSQL database that is designed to run high-performance applications at any scale. DynamoDB offers built-in security, continuous backups, automated Multi-Region replication, in-memory caching, and data import & export tools.
All these services are serverless so there are no servers to provision or maintain and no operating systems and software to patch and update. Let’s have a quick look at our simple data model.
Data Model
The Blueprint’s data model is made up of 3 entities - 'Author', 'Post', and 'Comment'. It allows us to store information about the author of a post, the content of the post, and comments about the post.
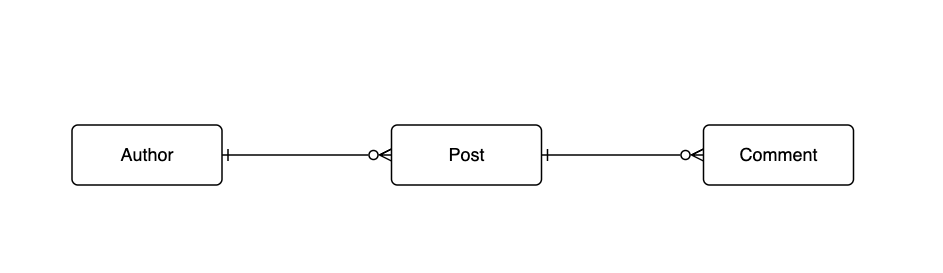
Relationships
'Author' has a one-to-many relationship with 'Post'
'Post' has a one-to-many relationship with 'Comment'
Author
The attributes for 'Author' is:
- id (partition key)
- title
- posts
- createdAt
- updatedAt
Post
The attributes for 'Post' is:
- id (partition key)
- title
- content
- authorId
- author
- comments
- publishDate
- createdAt
- updatedAt
Comment
The attributes for 'Author' are
- id (partition key)
- posts
- createdAt
- updatedAt
Access Patterns
Here are some access patterns accounted for by the blueprint:
- create Author by name
- get all posts by an Author
- delete Author by id
- get Post by id
- get all Posts by an Author
- get all Author Posts
- get Post by id
- get all Posts by an Author
- get all Posts by Authors
- create a Post by id
- update a Post by id
- delete a Post by id
- get an Author of a Post
- get all Comments for a Post
- create a Comment
Building the Project on CloudGTO
Step 1: Service Creation
After you log into your CloudGTO account, click on the “BUILD SERVICE” button to start the process which will take you to the Service Definition page.

On the Service Definition page, we will input our service name and a short description.
Next, select the GraphQL API Use Case and select the DynamoDB (Multiple data sources) Blueprint.
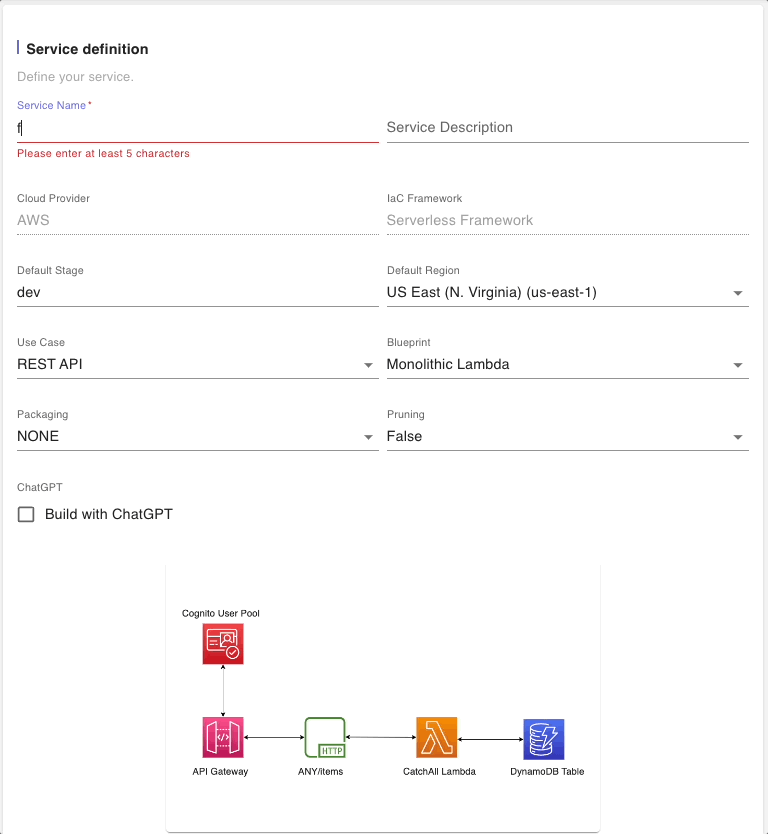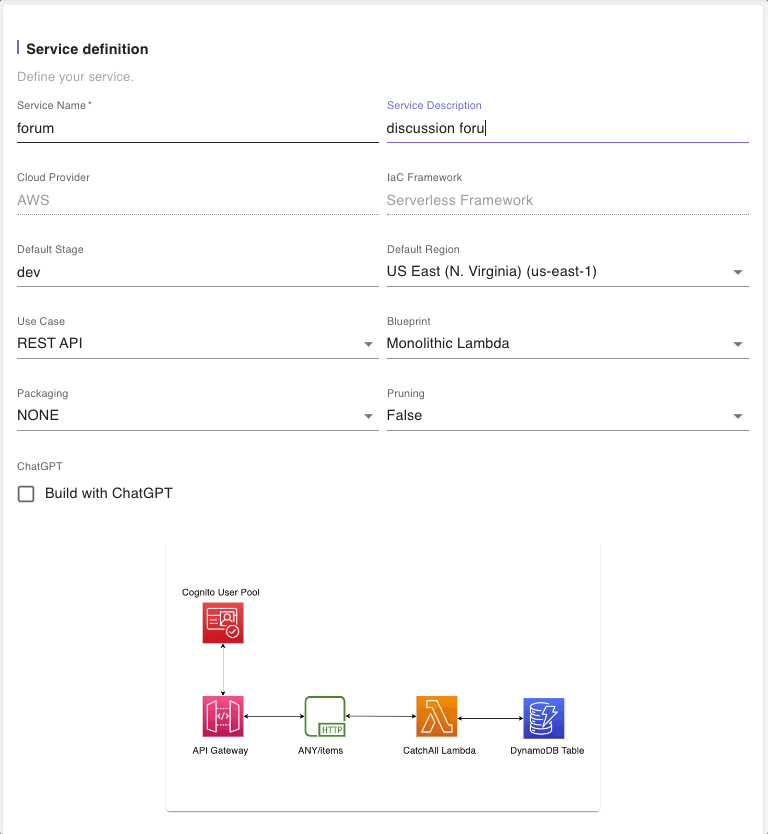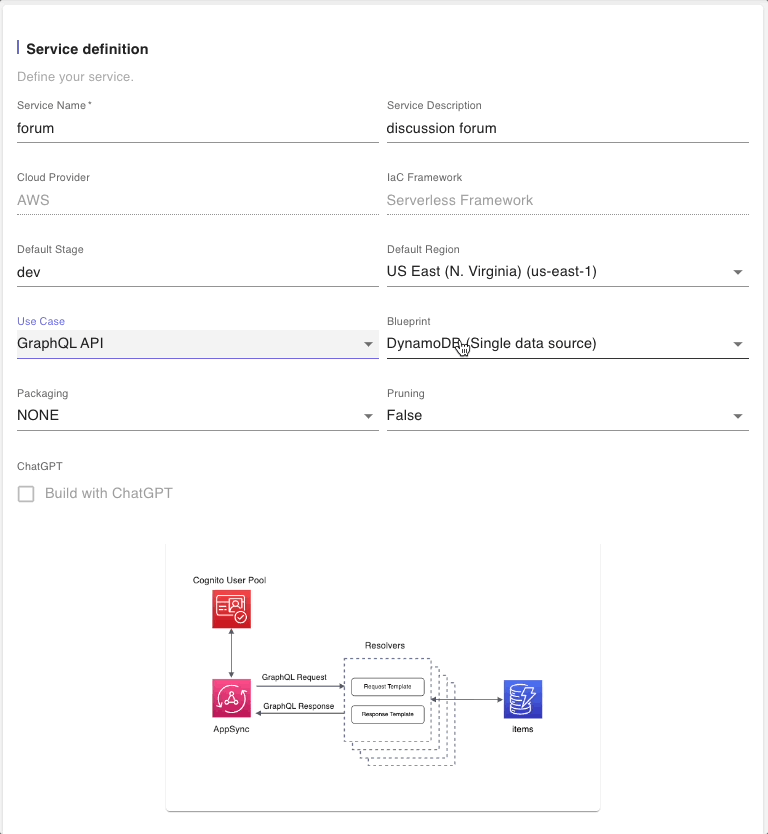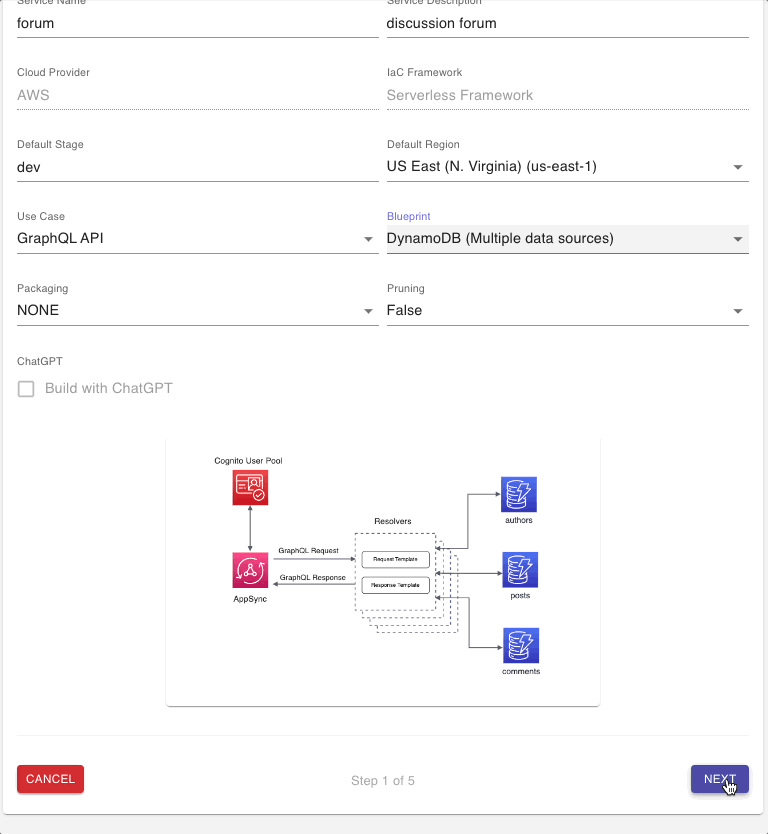
Take note of the architectural illustration which highlights the use of multiple DynamoDB tables. We will leave the defaults in the other fields and click on “NEXT” to go to the next step.
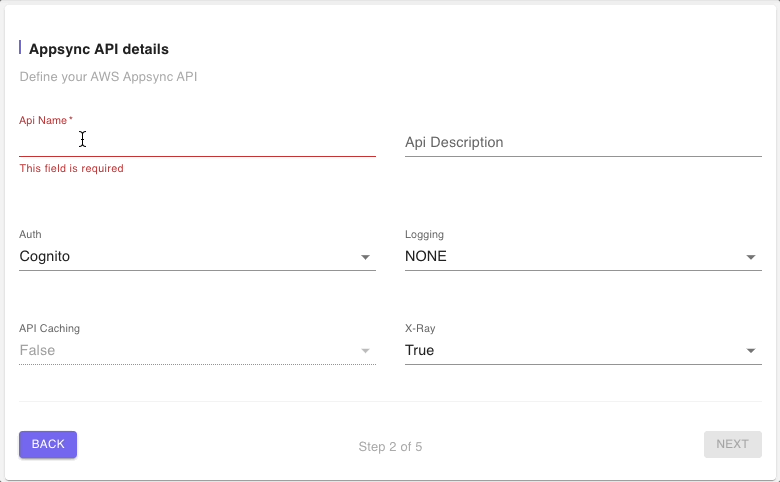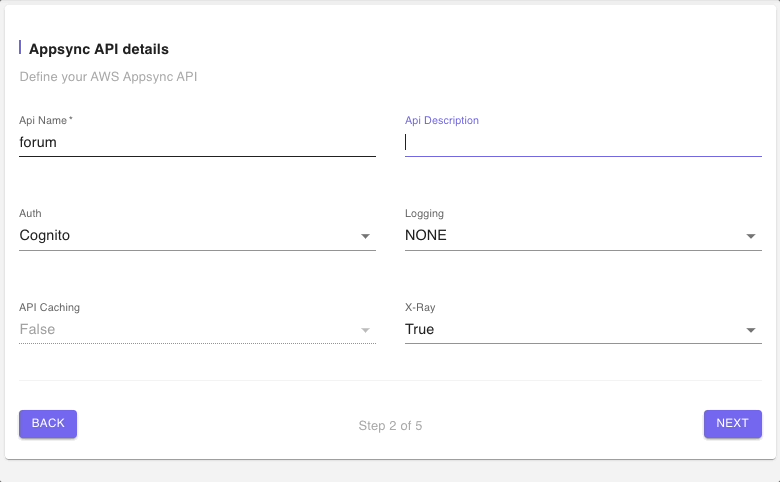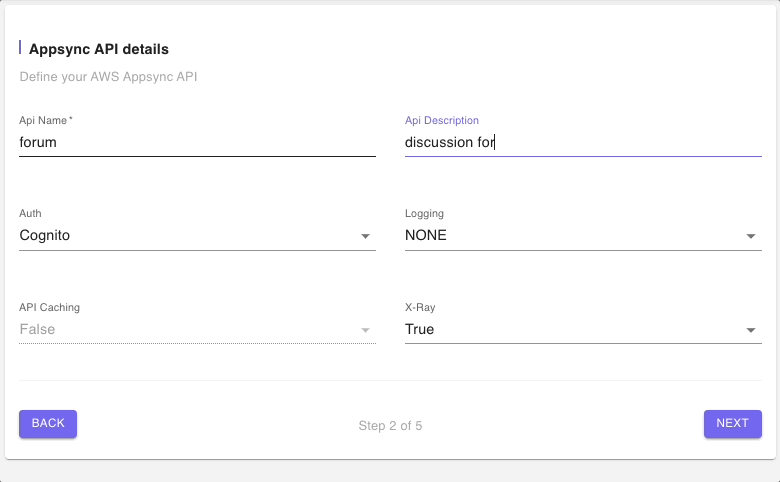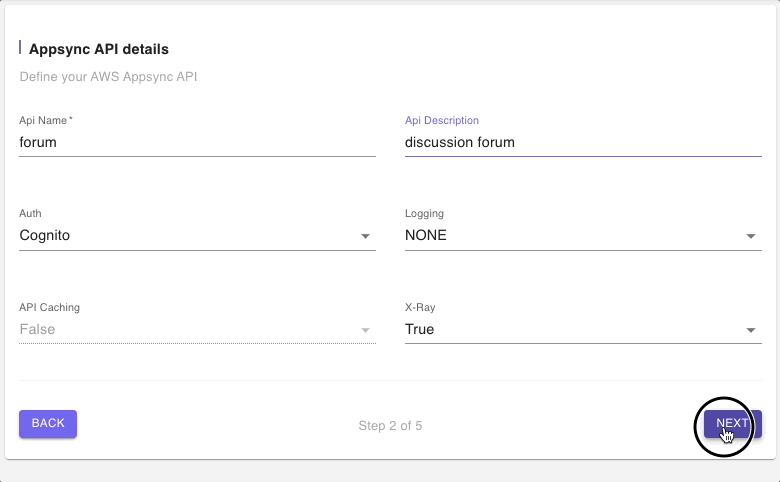
Step 2: AppSync API Details
In this step we will provide a name to the AWS AppSync managed resource. We will leave the other defaults such as Cognito for Auth and click on “Next”.
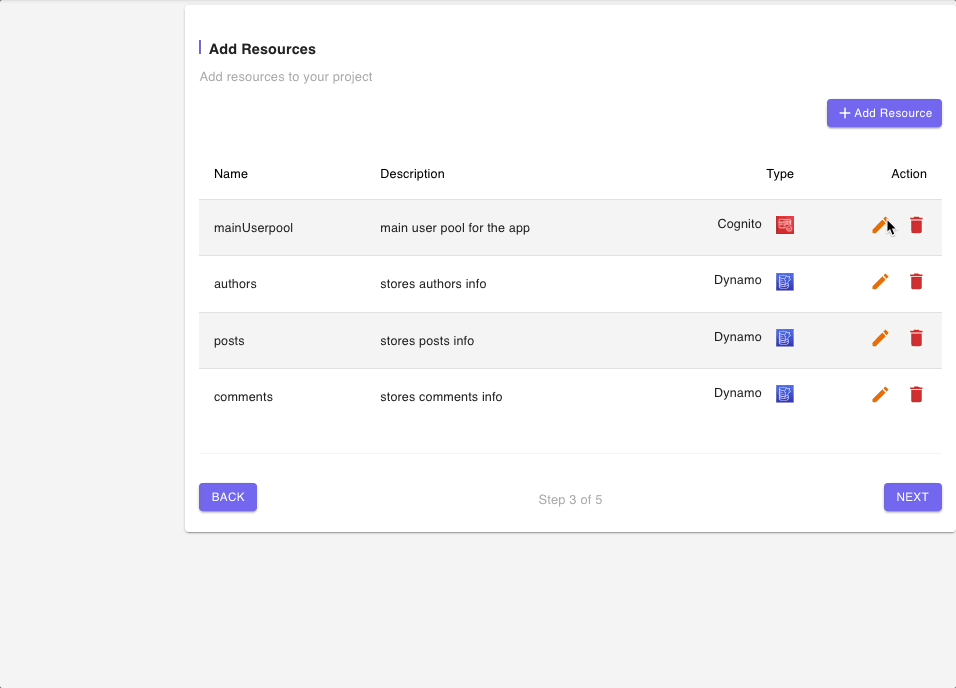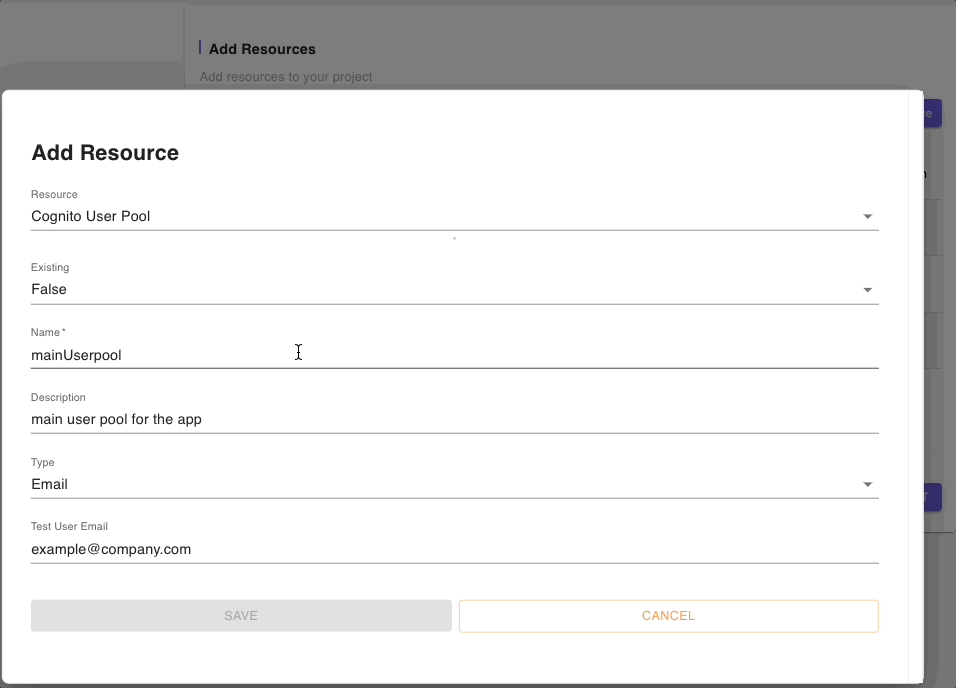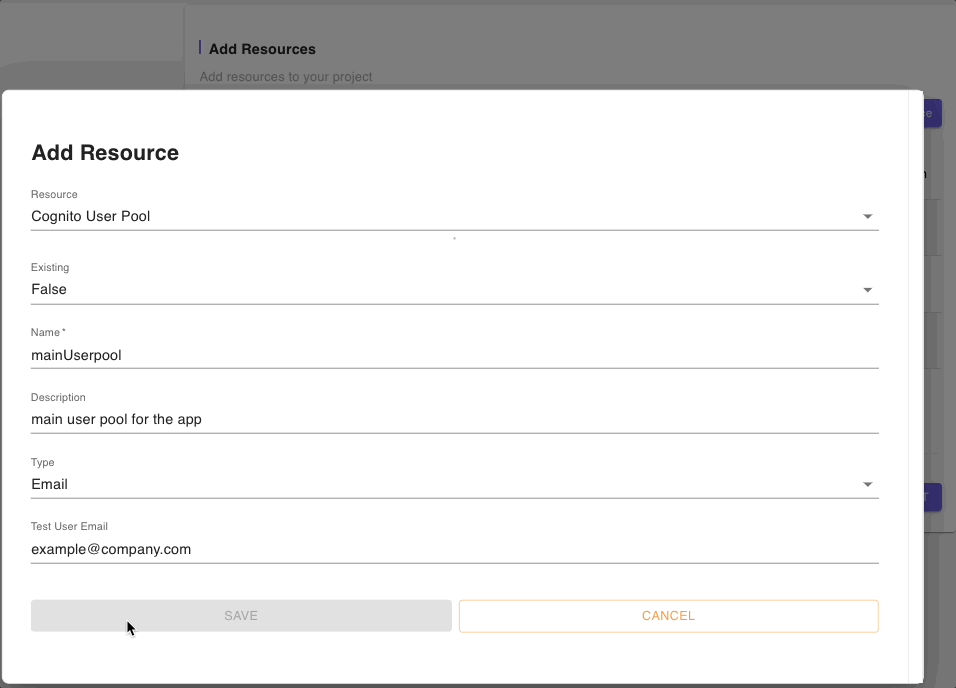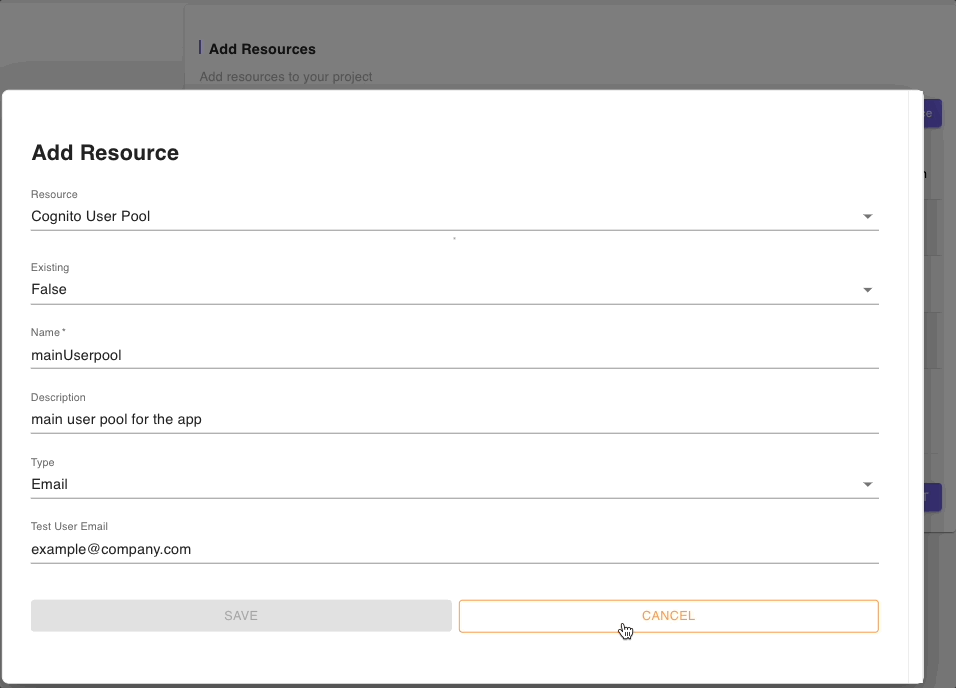
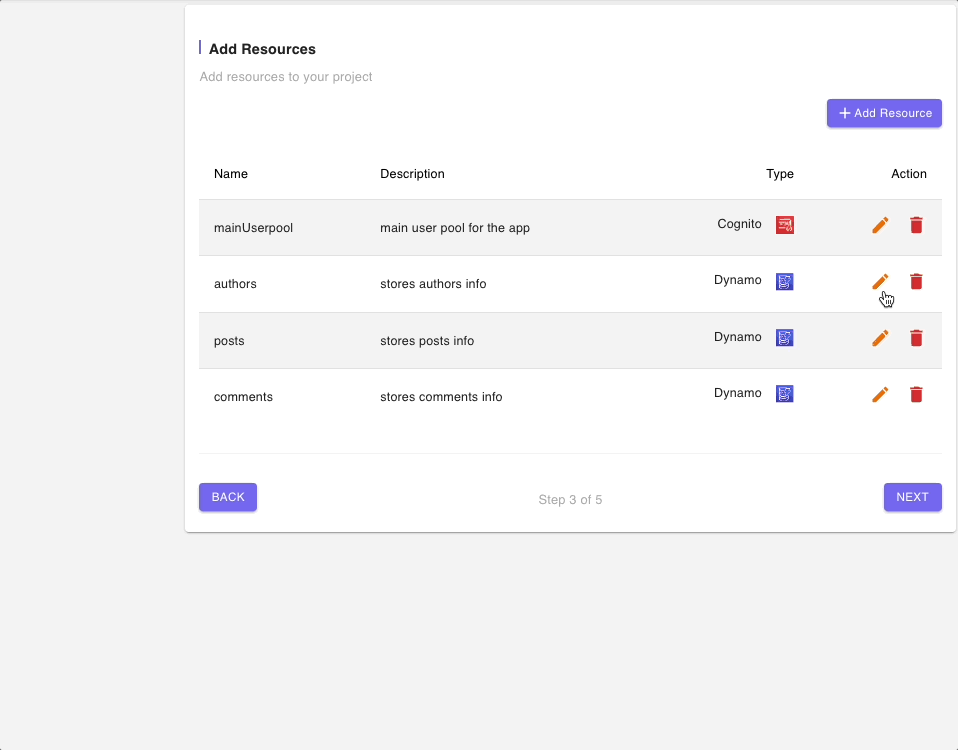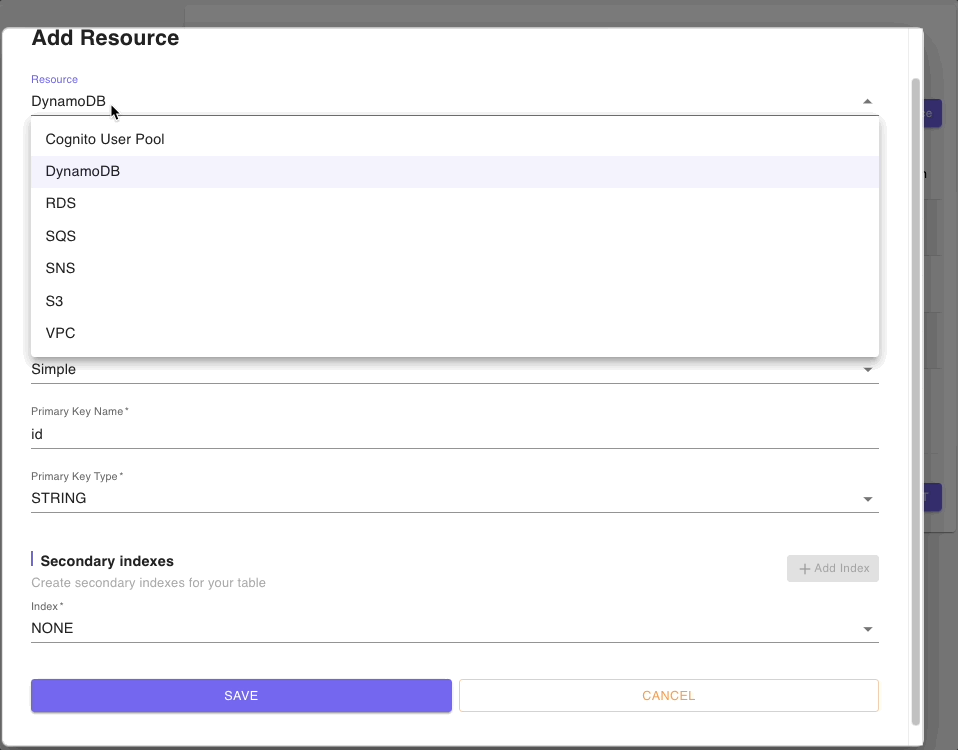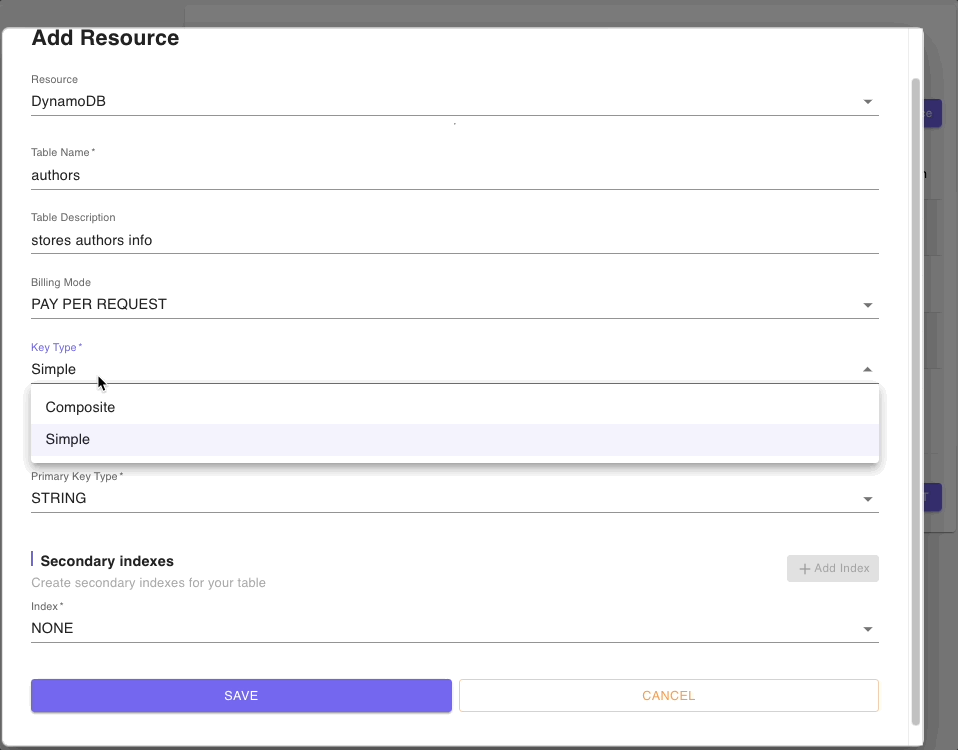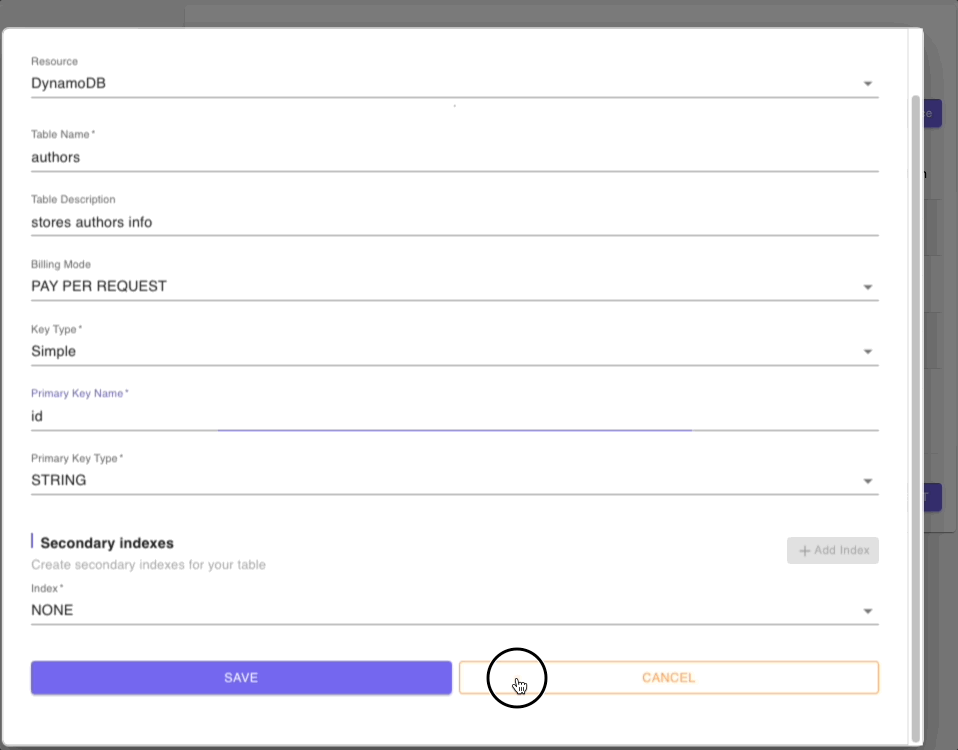
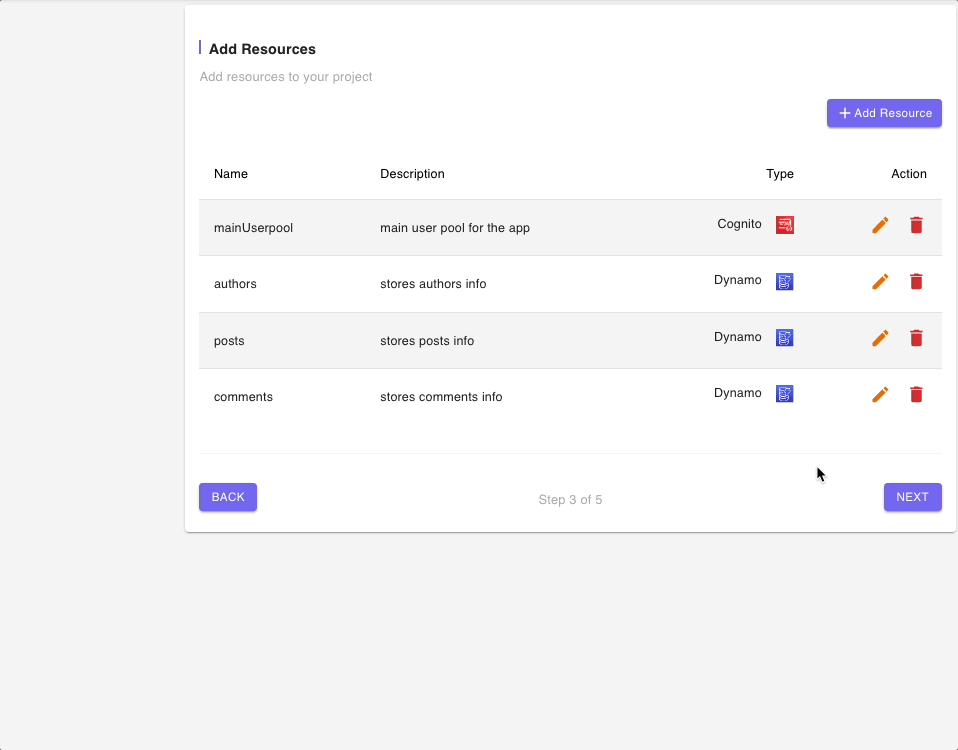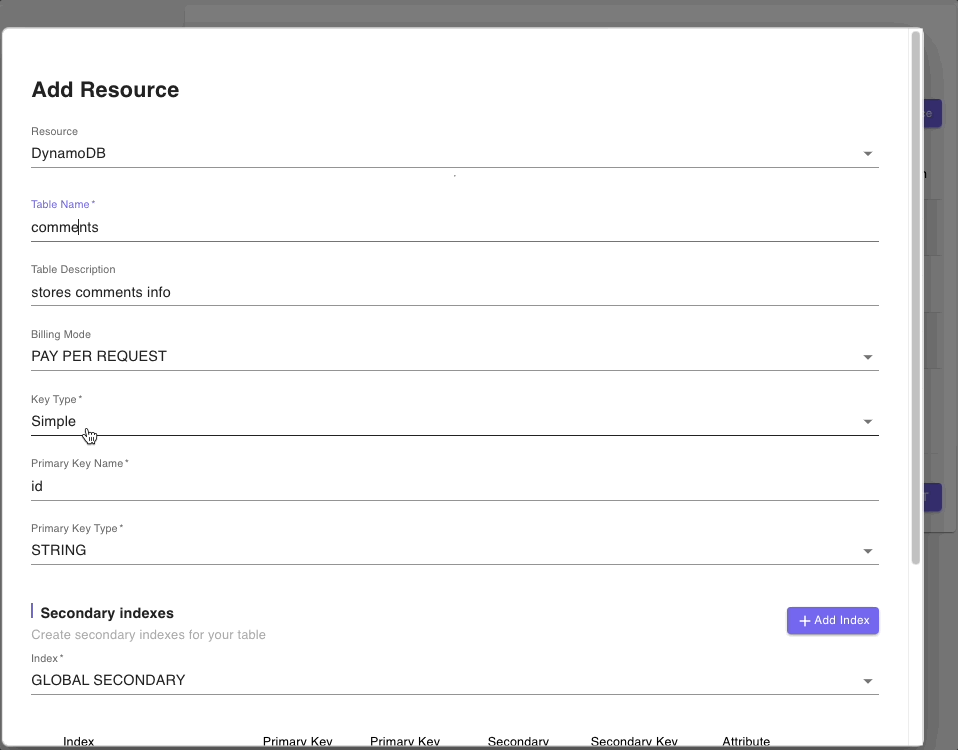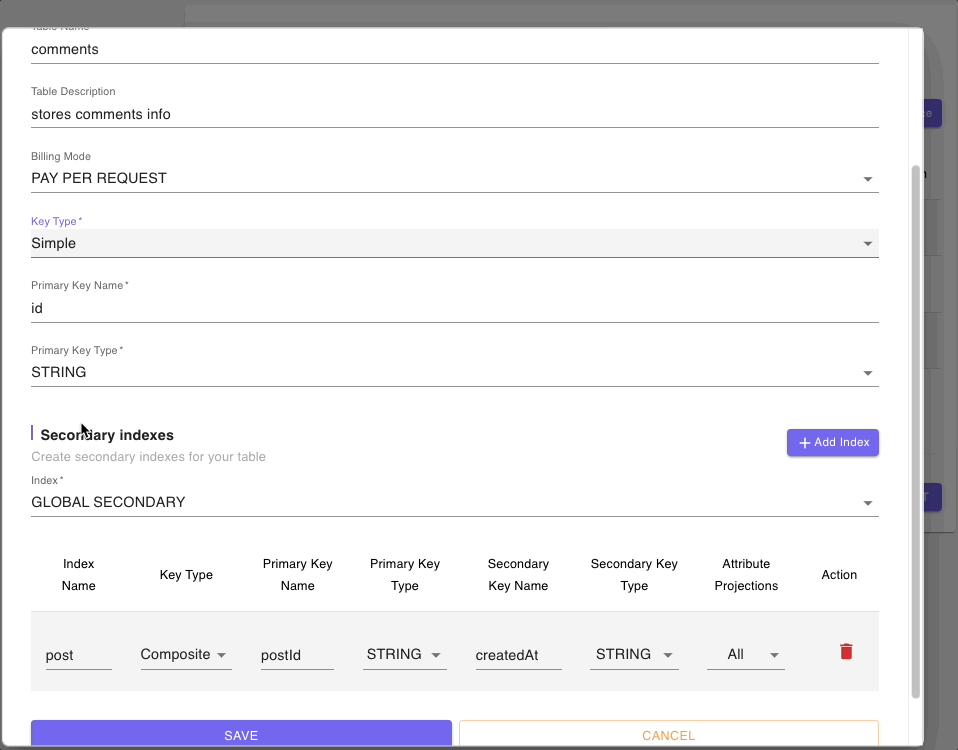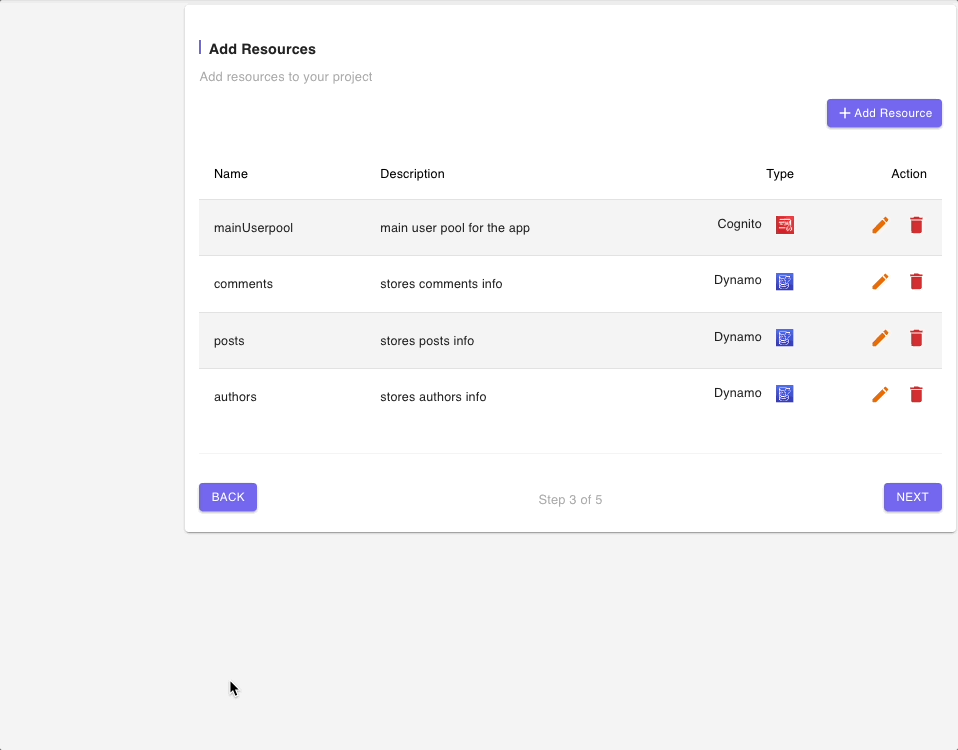
Step 3: Add Resources
The next page shows a list of all of the resources that will be built and deployed by this blueprint.

There is a Cognito User Pool which will be used to authenticate all calls to the GraphQL API endpoint as well as a DynamoDB table for each entity or model.
Since we are exploring the DynamoDB (Multiple data sources) Blueprint, we will not modify any of the resources but you can click on the “edit” icon to have a look at fields in the resources form.
Below is a snippet of the Cognito resource’s parameters:
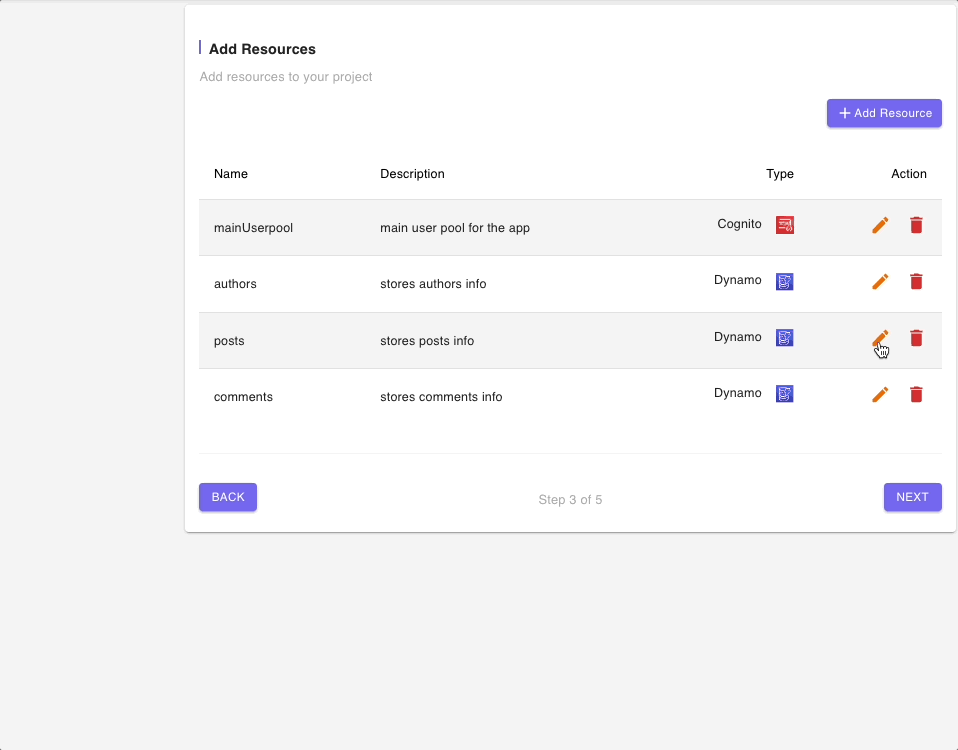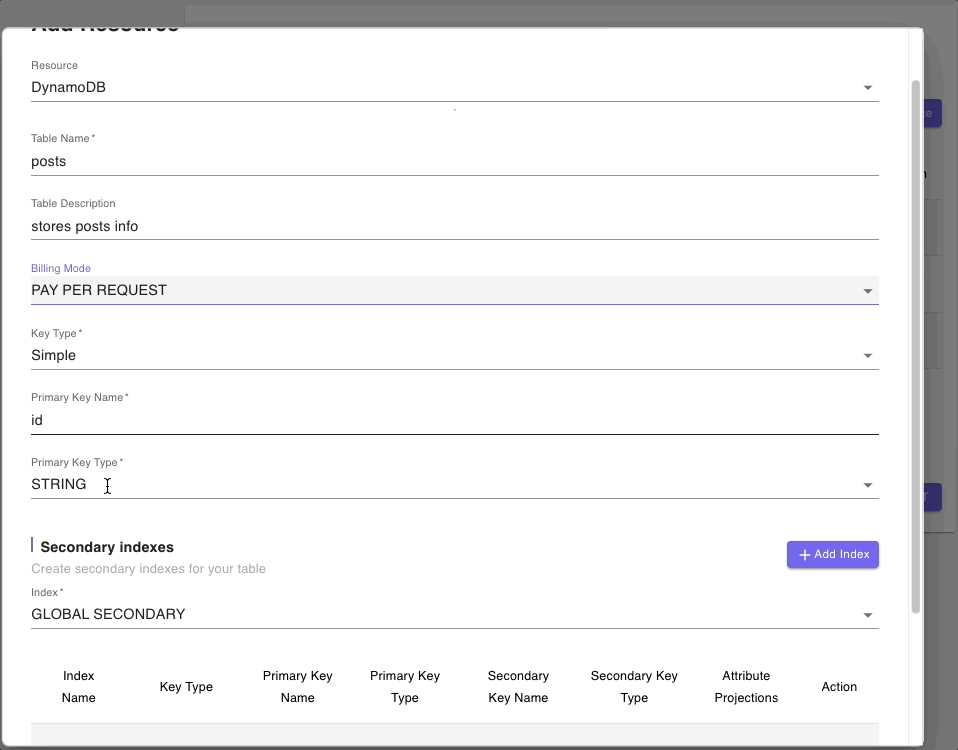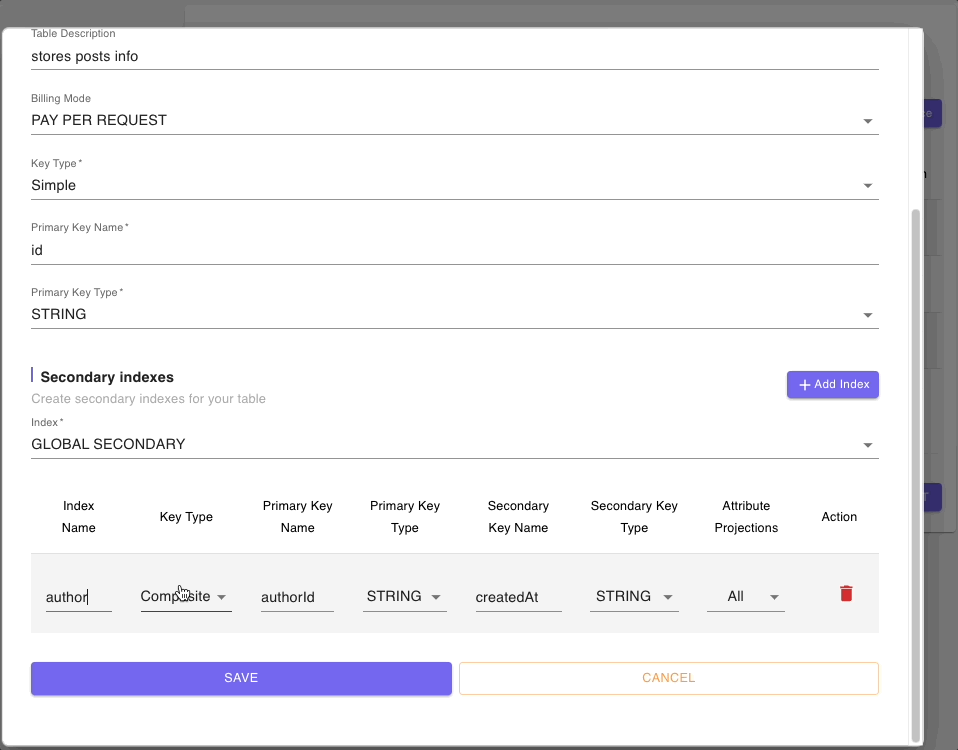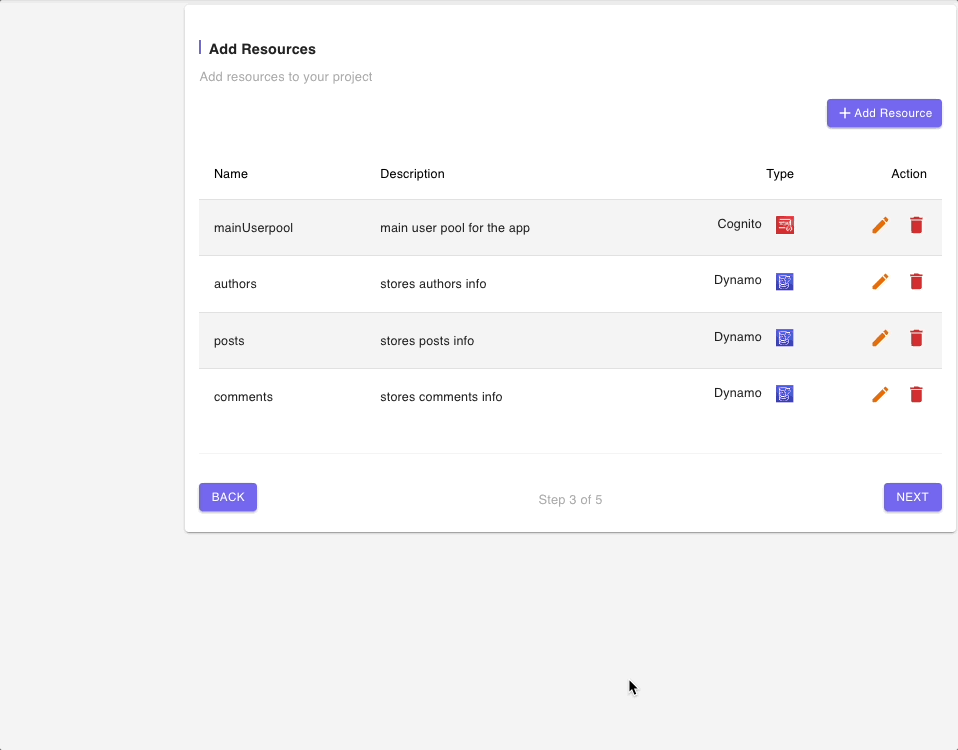
Below are snippets of DynamoDB tables resource forms for authors, posts, and comments tables:
Step 4: Models
The Models page shows a list of all of the models. There is a model for each entity.
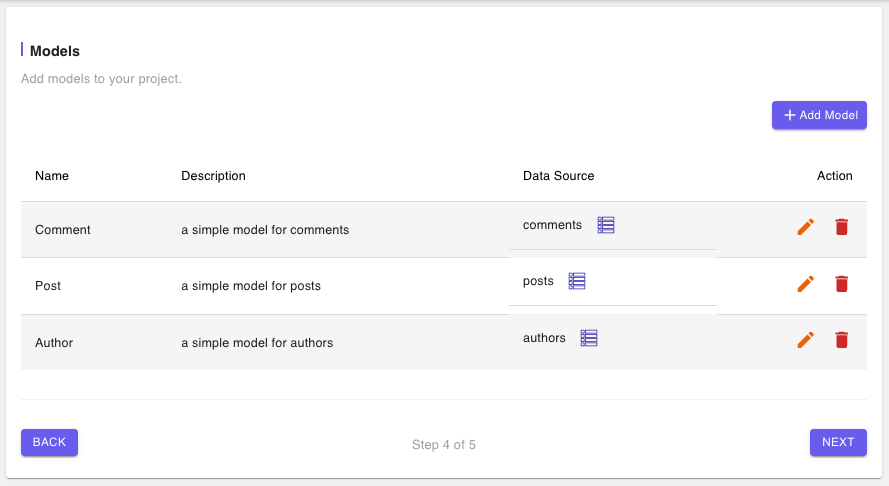
Let’s explore the Model configurations for each of the models starting first Author. Click on the “edit” icon to reveal the Model form.
The first section of the Model form is basic information like the name and description of the model as well as the DynamoDB table that stores the information for the model.
The next section is the Model Fields where we can see the various fields for the Author model.
The final section is for the relevant resolvers for the model.
The Model form for the Post and Comment models have the same sections as described above so you can explore them to see the options available for each form field. But since we have a lot on the default Blueprint, we won’t edit any of the forms.
Click on “NEXT” to continue to the Summary page
Step 5: Summary
The Summary page provides brief information on what will be deployed as well as some deployment notes on how to deploy with automation scripts to AWS.

Click on “BUILD” to start building the project files.
Step 6: Download the project
The Build process takes a few seconds to build all of the files for the project. The files are displayed on the Service Preview page. We can have a look at the folders and preview the files on the Code Preview tab

The Architecture Preview tab shows a diagrammatic representation of all of the resources and how they are interconnected together

This is the last step required to build a GraphQL API with multiple data sources on CloudGTO using the DynamoDB (Multiple data sources) Blueprint. The next step will be to download the project for possible further local development and deployment to AWS.
Deploying the Blueprint
The downloaded project files are zipped up so the first step would be to unzip the files and open them in your IDE of choice.
The Blueprint already contains IaC and some application code which is ready to be deployed to AWS but let’s first of all look at the “README” file which has some instructions that can make the deployment and testing of your CloudGTO project seamless.

Before deploying, ensure you have all the prerequisite requirements mentioned above.
Run 'npm run setup' to install, format, and deploy to AWS.
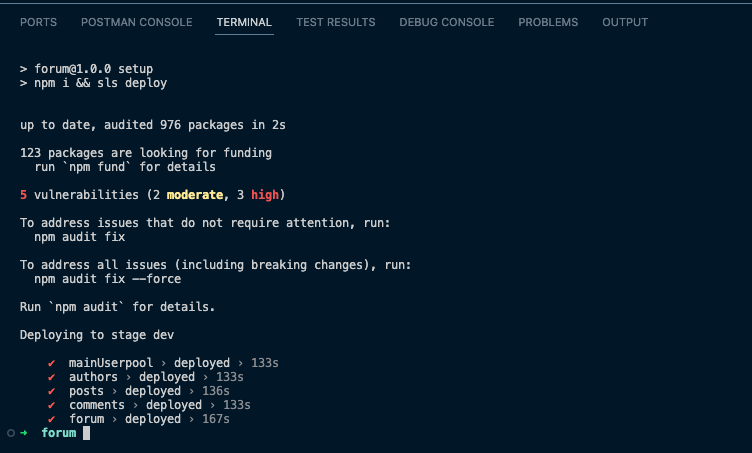
To list a list of all the resources deployed to your AWS account, you can run 'npx sls info'
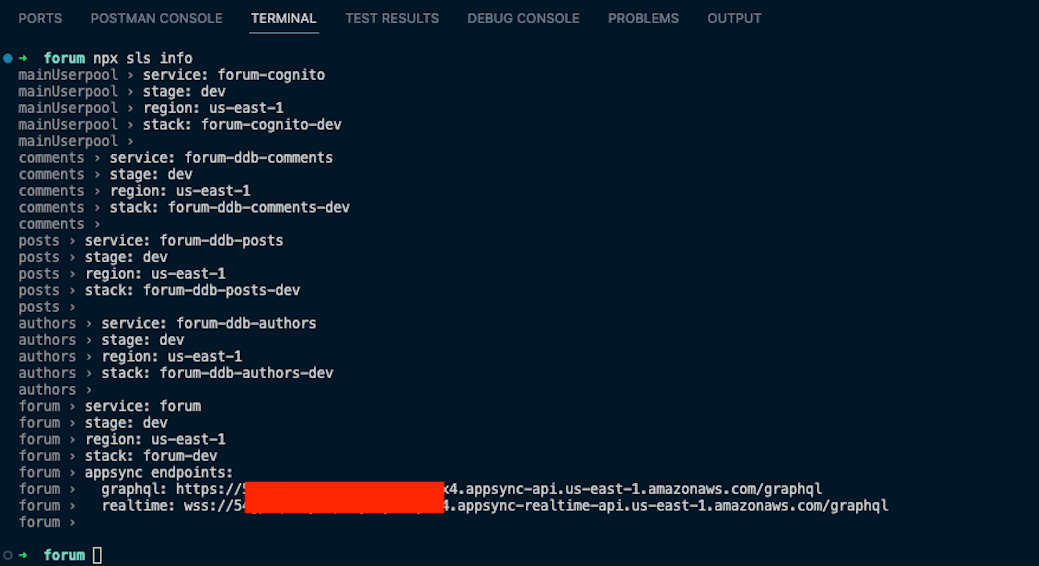
Let’s head over to the AWS AppSync Console to have a look at the schema and resolvers.
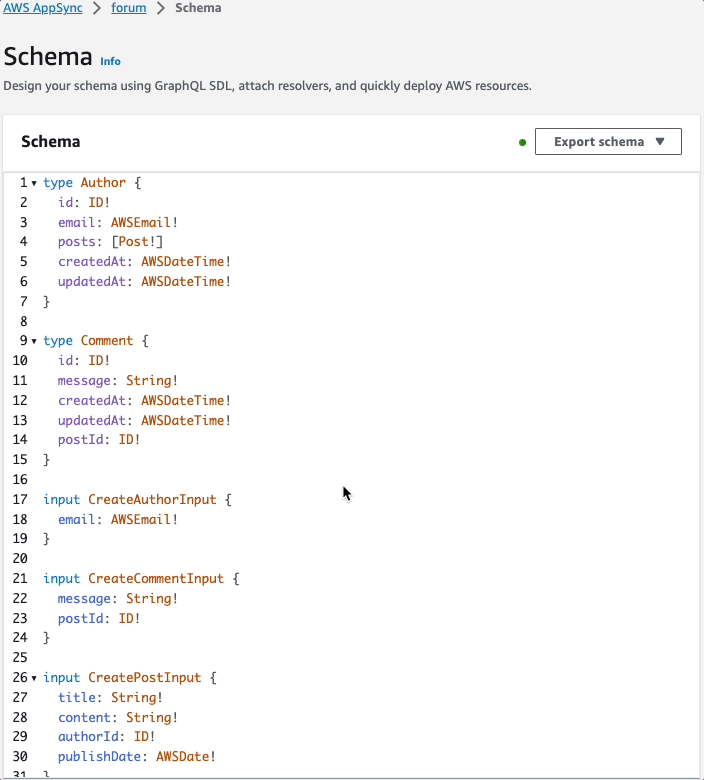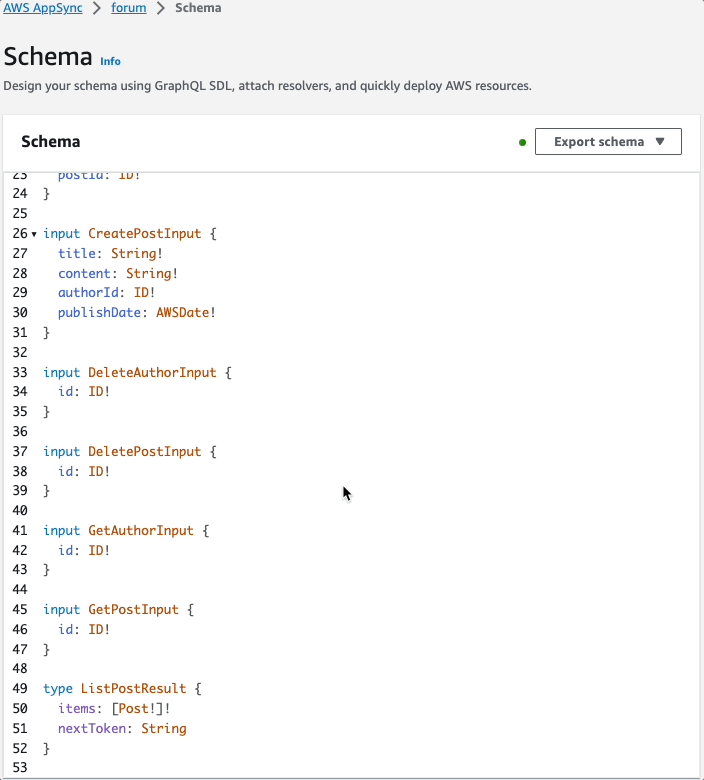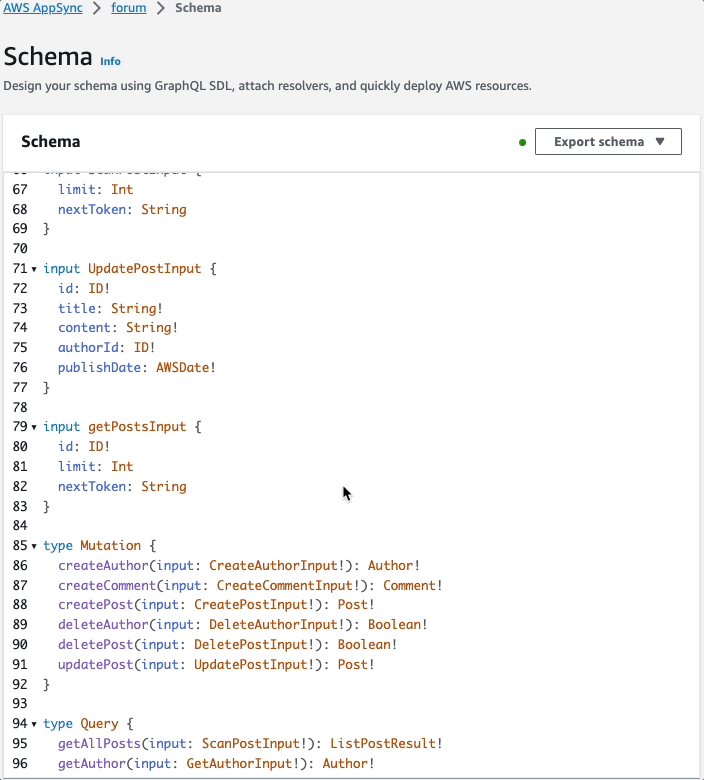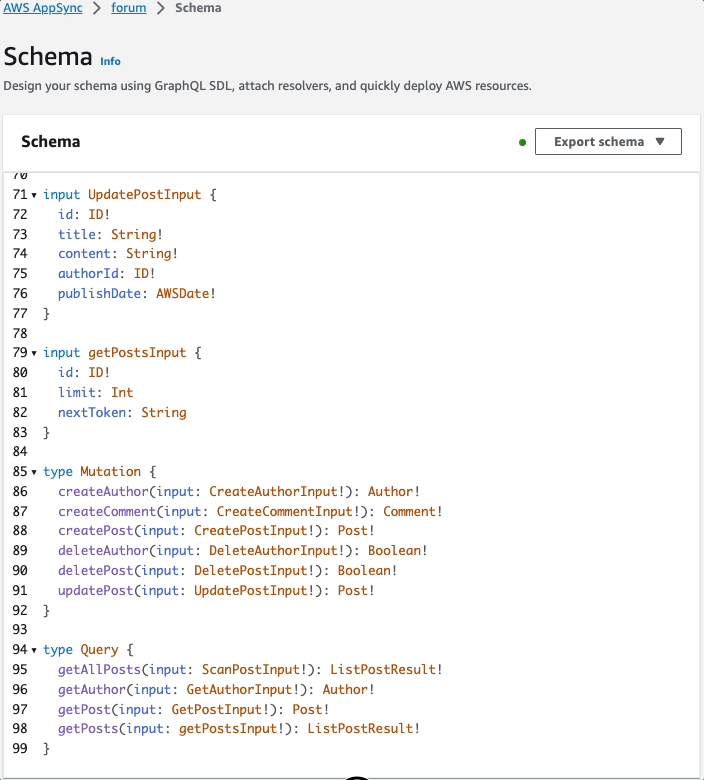
Here is the schema file stitched together with all of the types:
We can also see the 3 data sources:

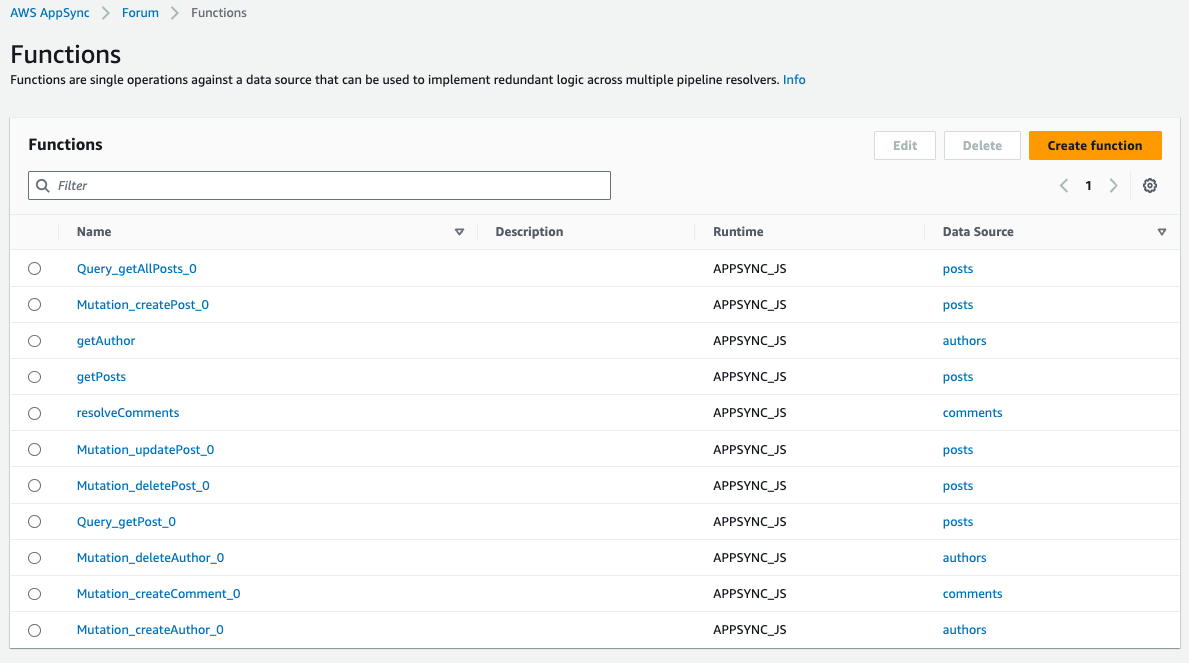
And finally, the resolver functions:
End-to-end tests with GraphBolt
Setting up GraphBolt
GraphBolt is a desktop tool that helps you develop, test, debug, and manage your AWS AppSync APIs. I like GraphBolt because it automatically uses your AWS CLI profiles to pull all the information relevant to your AppSync API’s without requiring you to open multiple pages on the AWS Console.
It is currently in public beta and is free at the time of this post. The free version will suffice for our preliminary tests.
When you open the GraphBolt desktop application, it will automatically pick up one of your AWS CLI profiles. Clicking on the search bar will expose all of the AppSync APIs in your account in the default AWS Region setup for your AWS CLI profile. In our case, we can see our 'forum' AppSync GraphQL API. Click on it to start configurations.
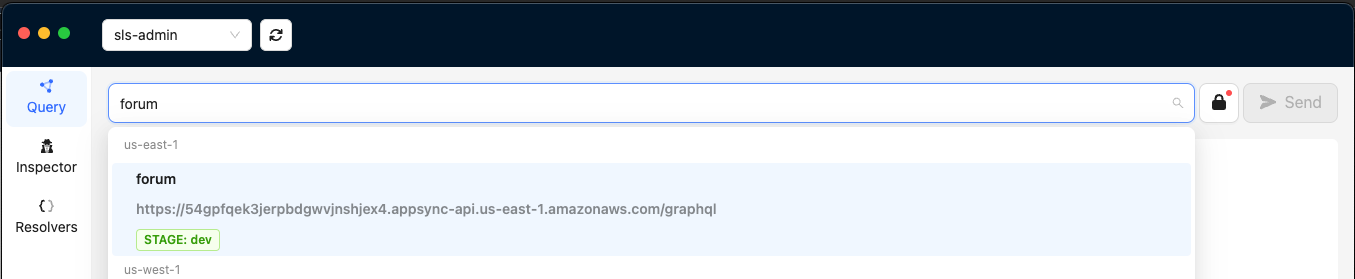
Next, we will click on the padlock icon on the right of the address bar which will display an Authentication modal. The User Pool and App Client will automatically be selected since these are the only ones available for our API.
To get the Username and Password, open your terminal and run: 'npm run signCognito'. This script will execute a series of bash commands to sign up and sign in the cognito user and return the login details.
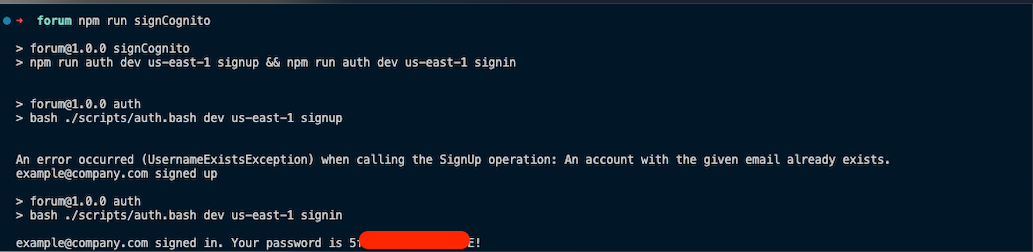
Copy the Username and Password. Next, paste them into the Authentication modal and click on “Login”.
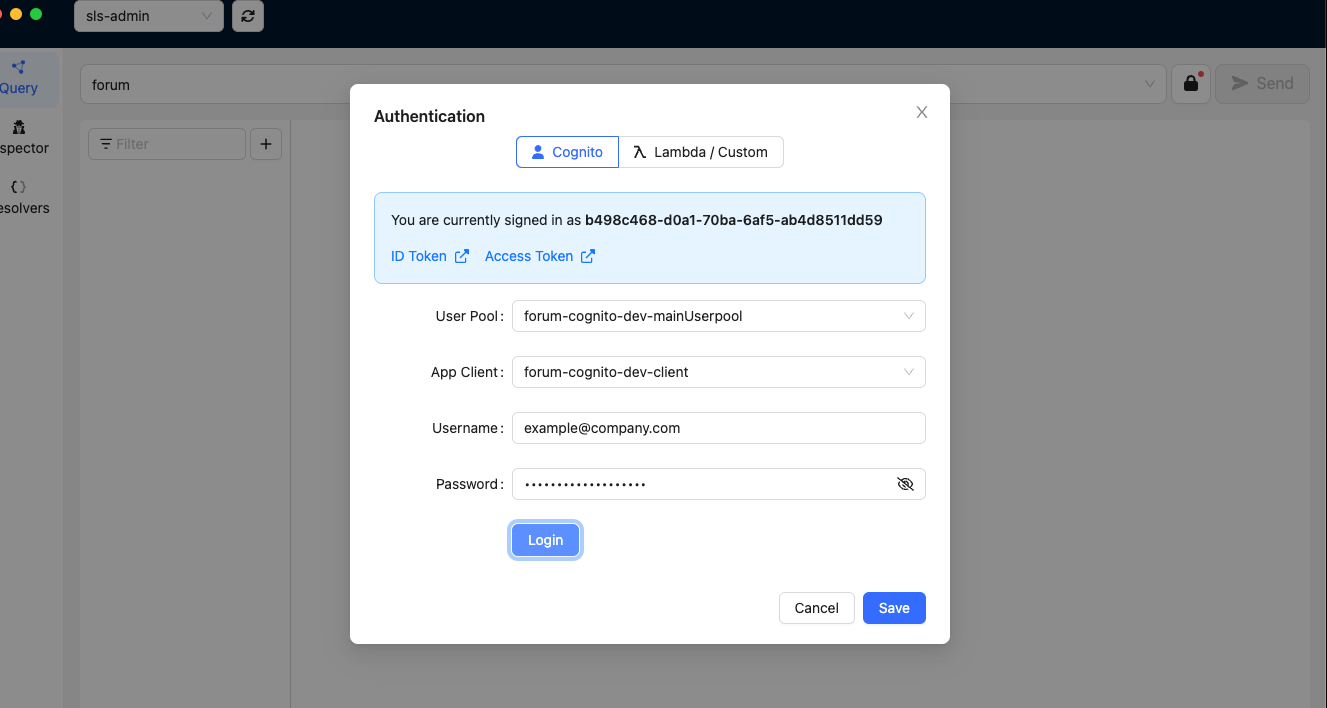
Once the login is successful, click on “Save” to exit the Authentication modal. We are now ready to test some of the GraphQL queries and mutations with GraphBolt.
Now we are ready to test our resolvers. For demonstrative purposes, we are going to do the following tests:
- create an Author
- get an Author
- create a Post
- get a Post by id
- get all Posts by an Author
- get all Posts by all Authors
- create a Comment
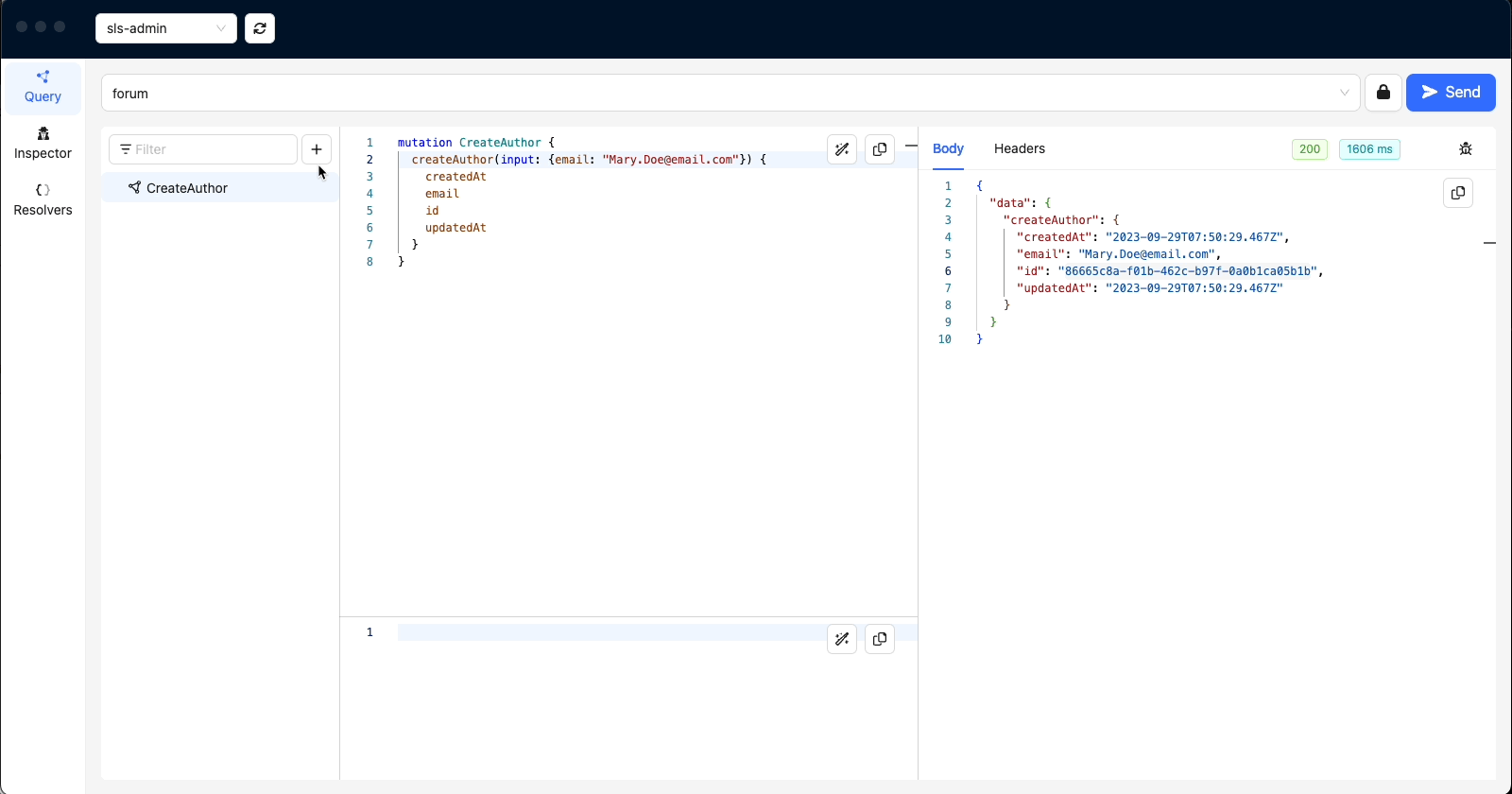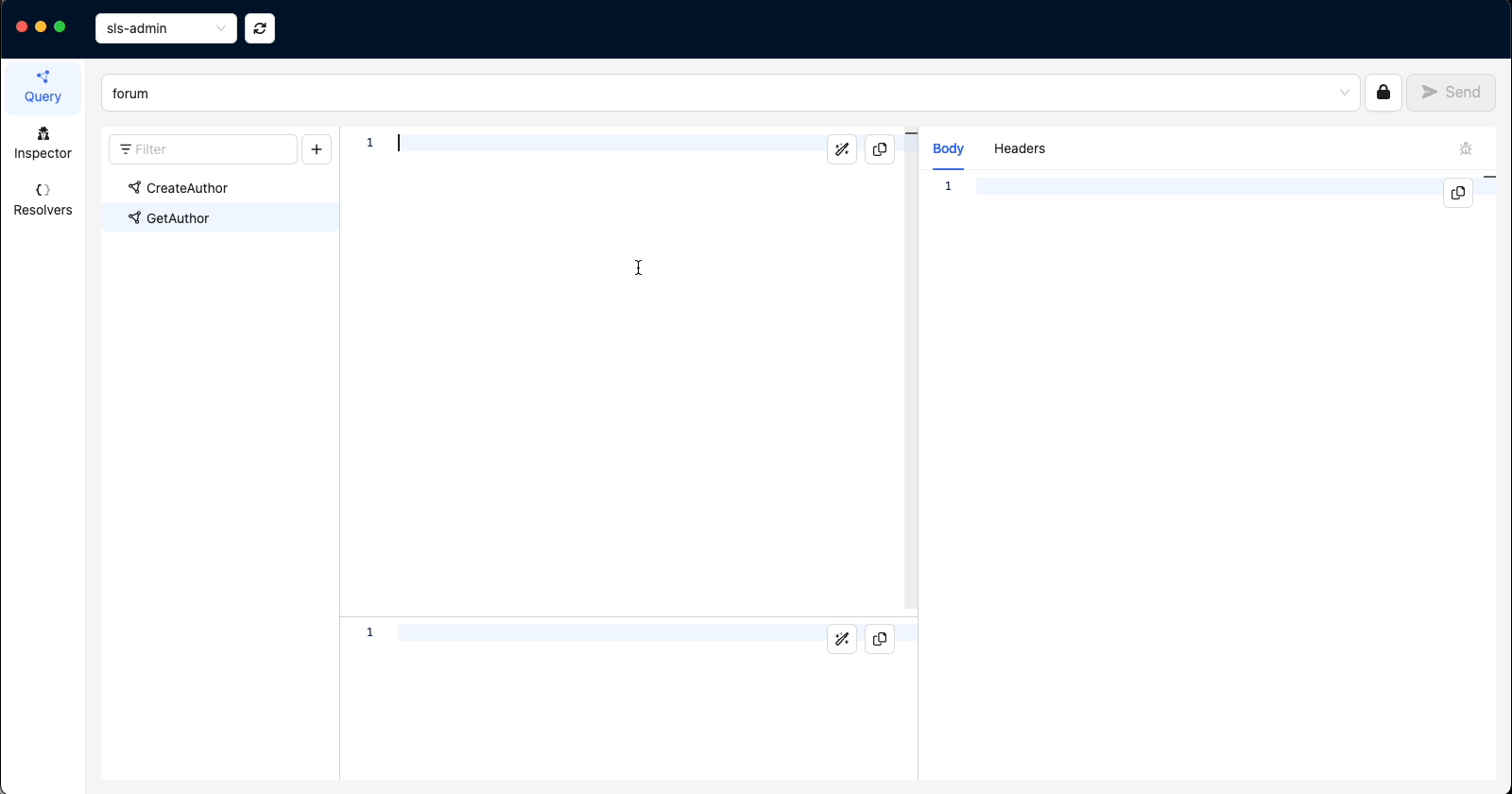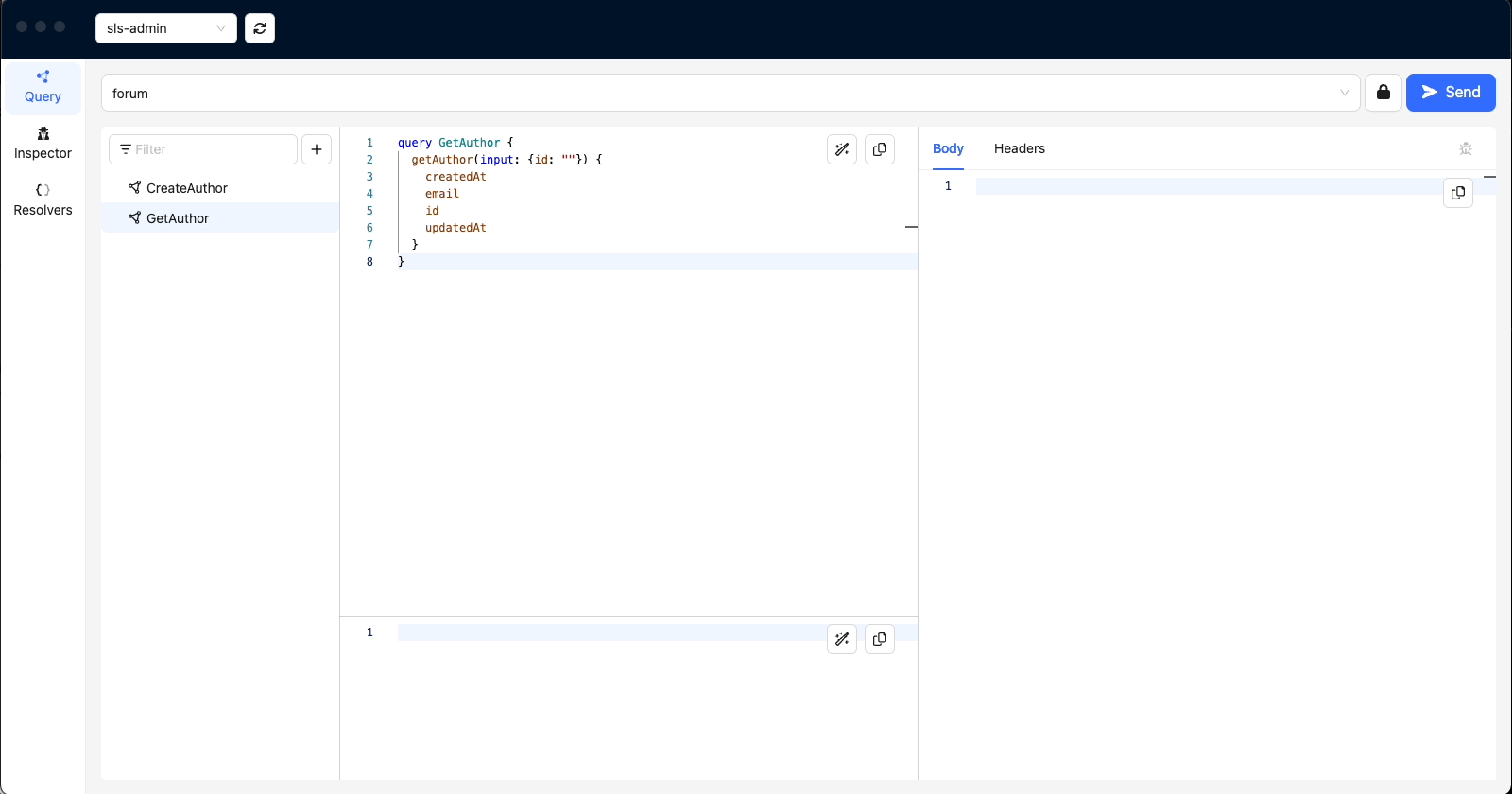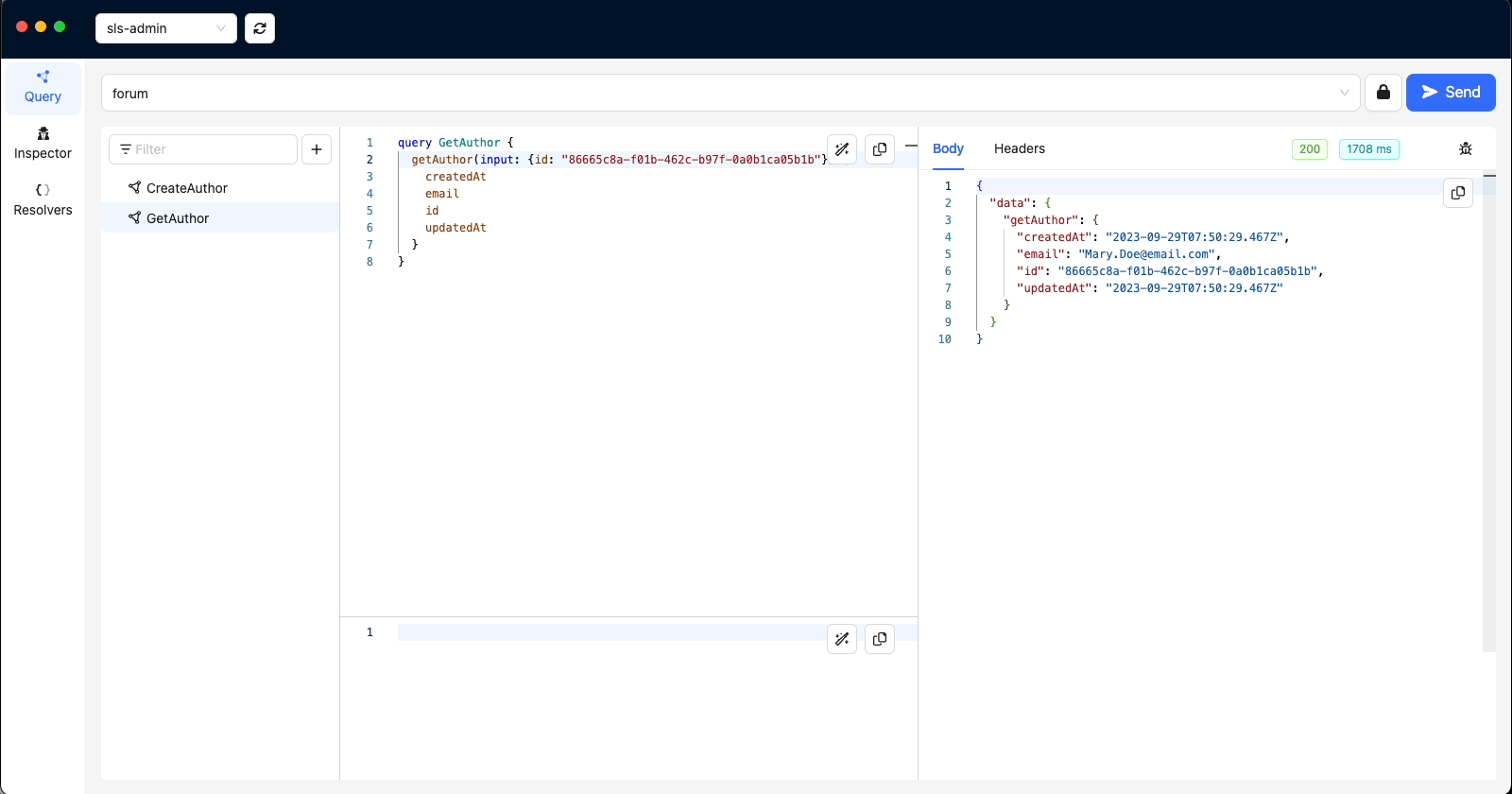
'CreateAuthor'
We are going to create 2 Authors using the following mutations:
To create the mutation in GraphBolt, click on the Add Operation button and provide the necessary information.
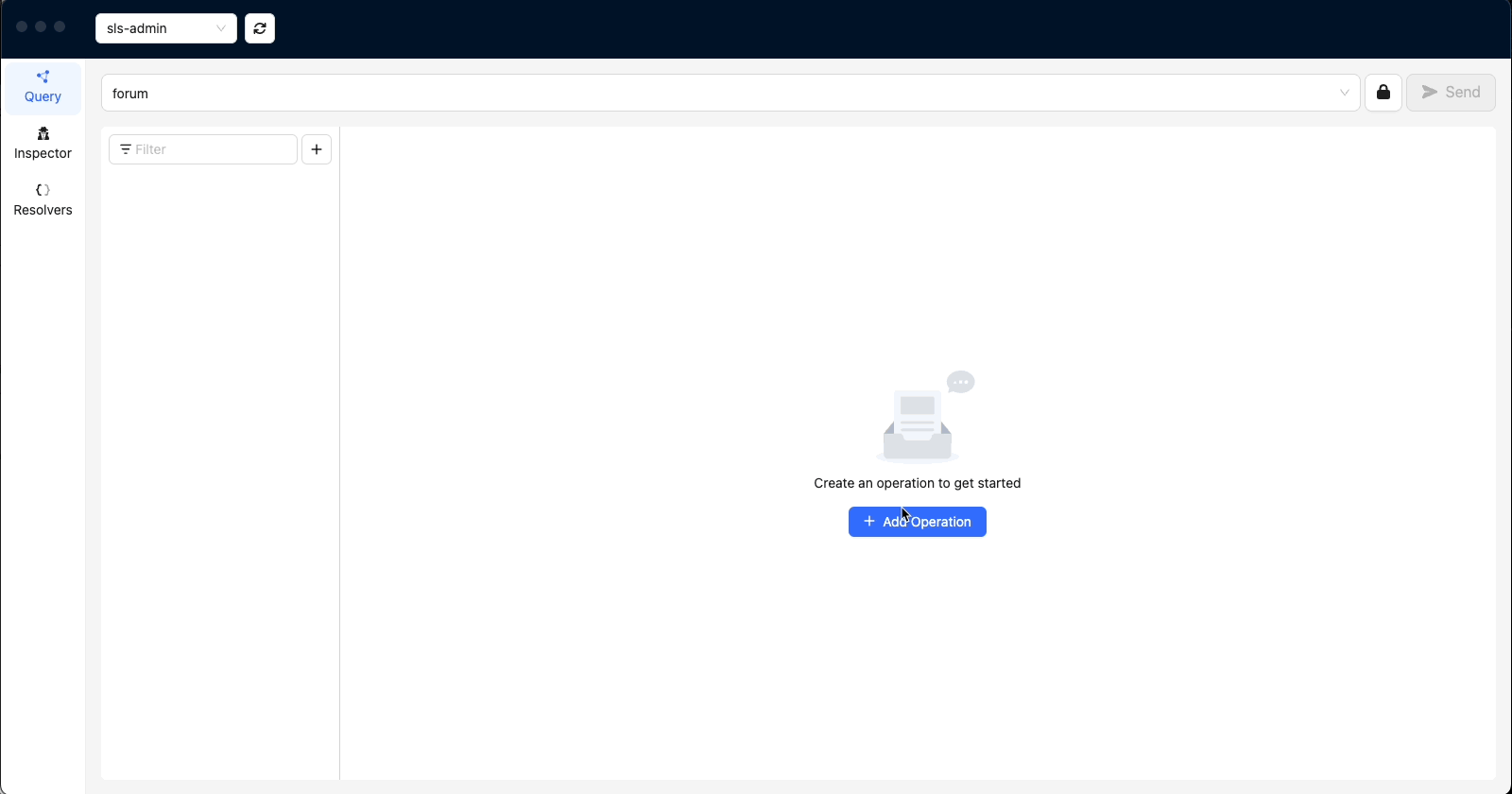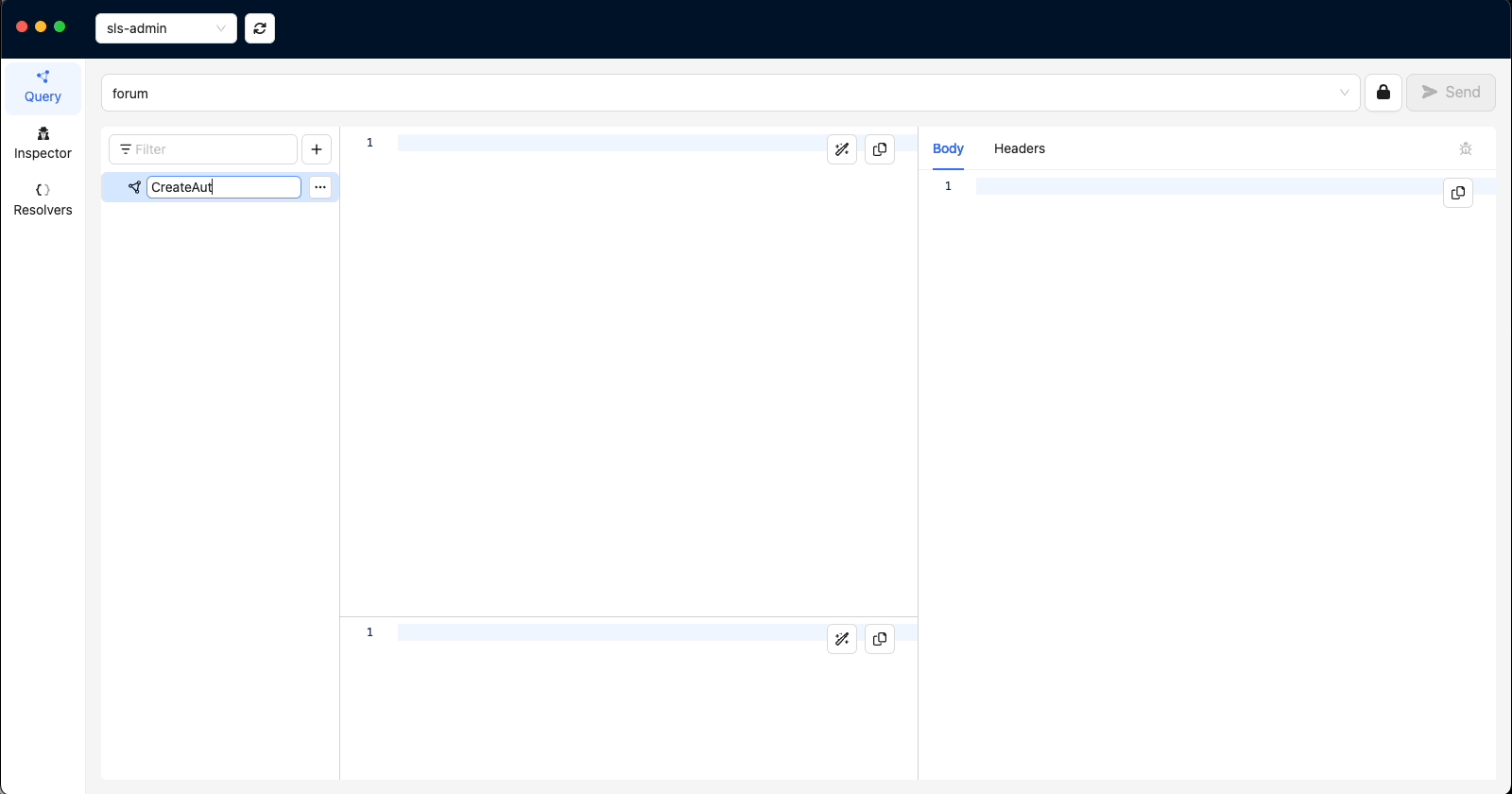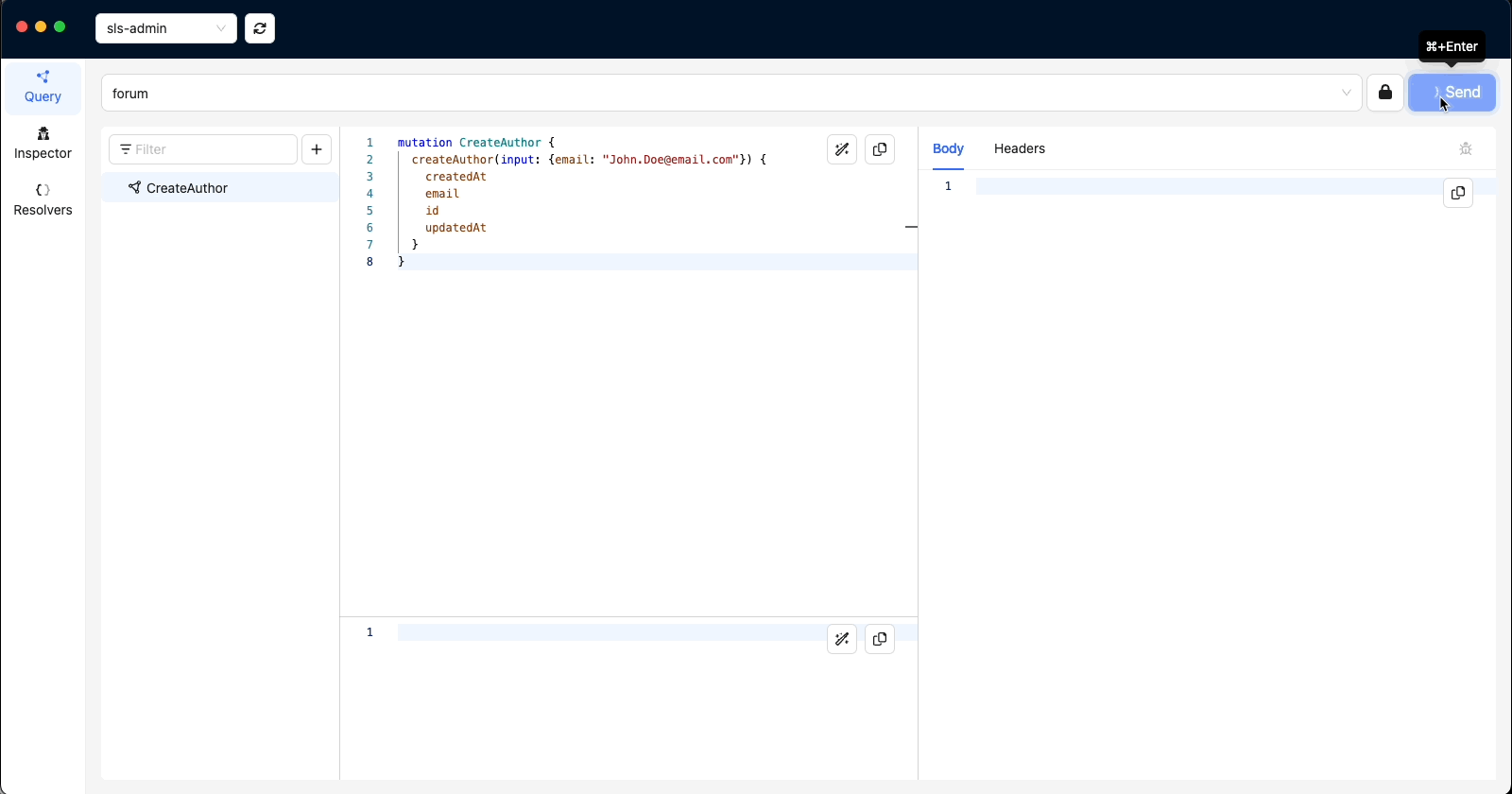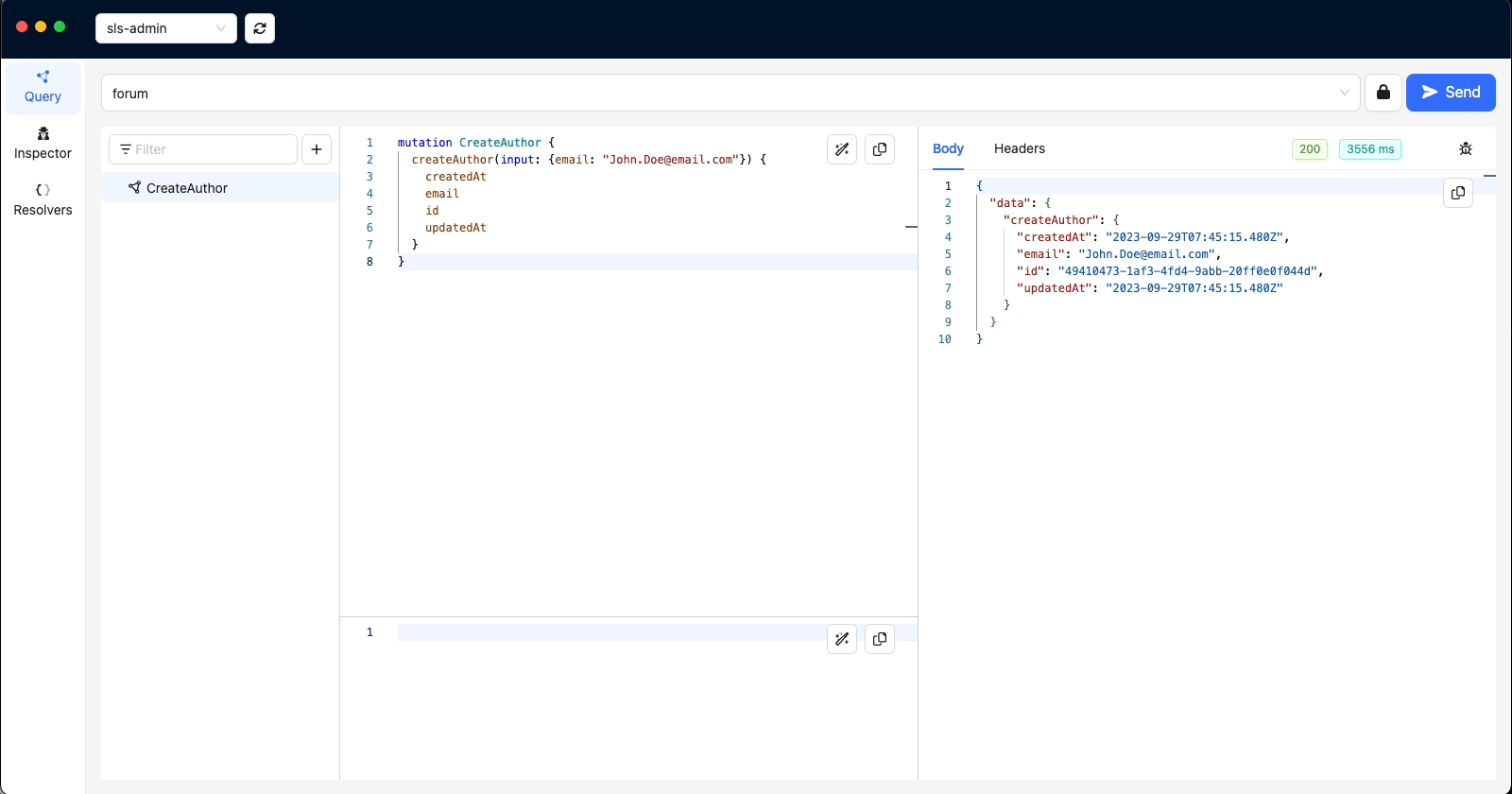
Here are the results when we execute the mutations in GraphBolt
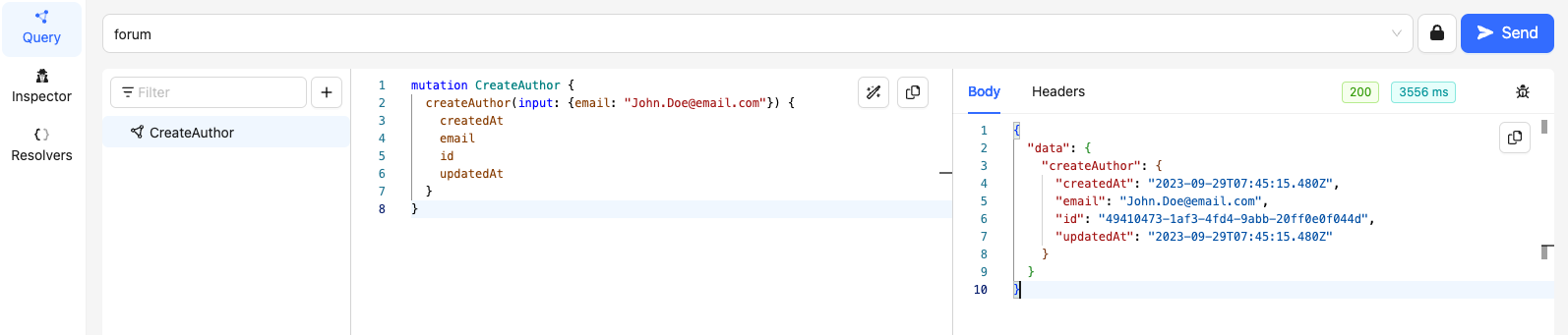
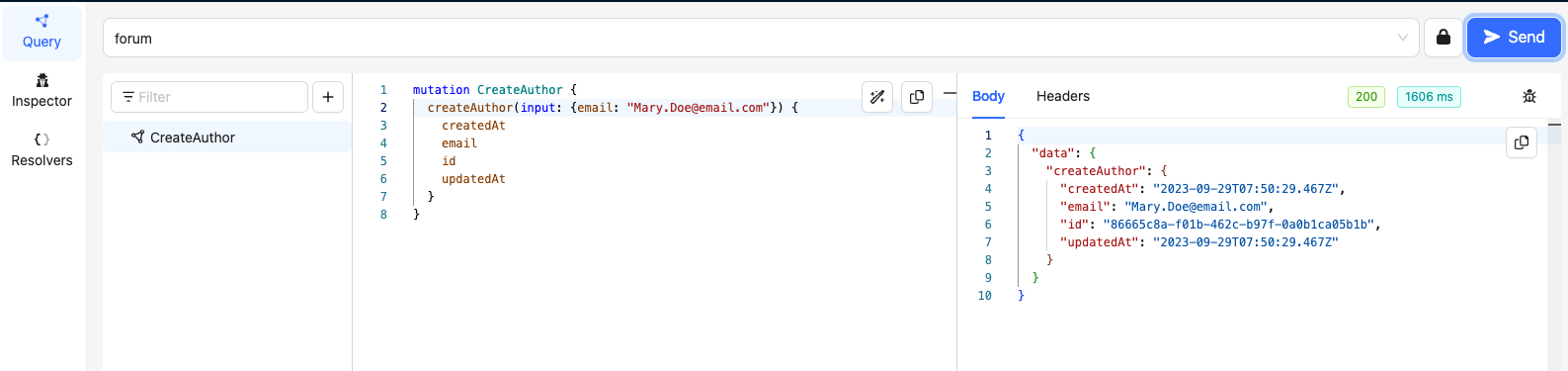
Take note of the ids for Authors - John Doe and Mary Doe (49410473-1af3-4fd4-9abb-20ff0e0f044d & 86665c8a-f01b-462c-b97f-0a0b1ca05b1b)
'GetAuthor'
We will use the ids to get the Recipes we just created.
'CreatePost'
We will use the following mutations to create posts for our Authors
Here are the results:
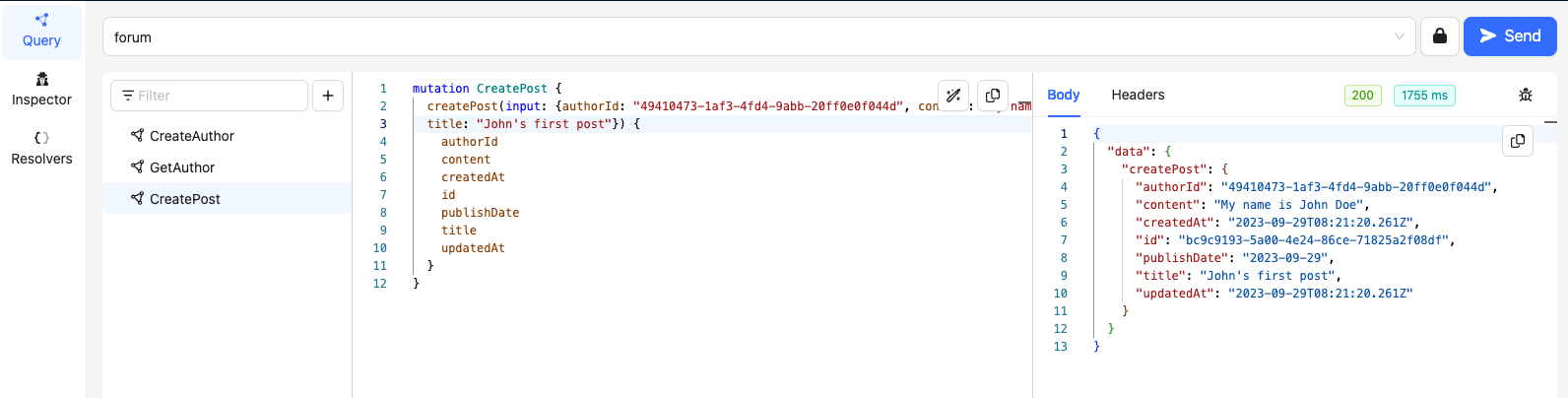

'GetPost'
Testing the 'GetPost' resolver:
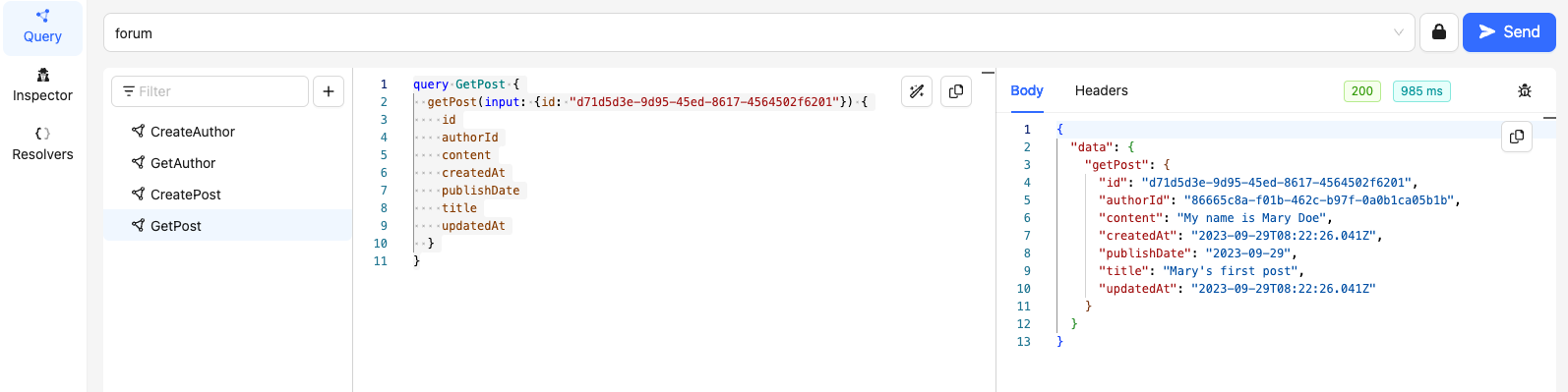
'GetPosts'
This will query all posts by an Author. Let is query all posts by Mary Doe:
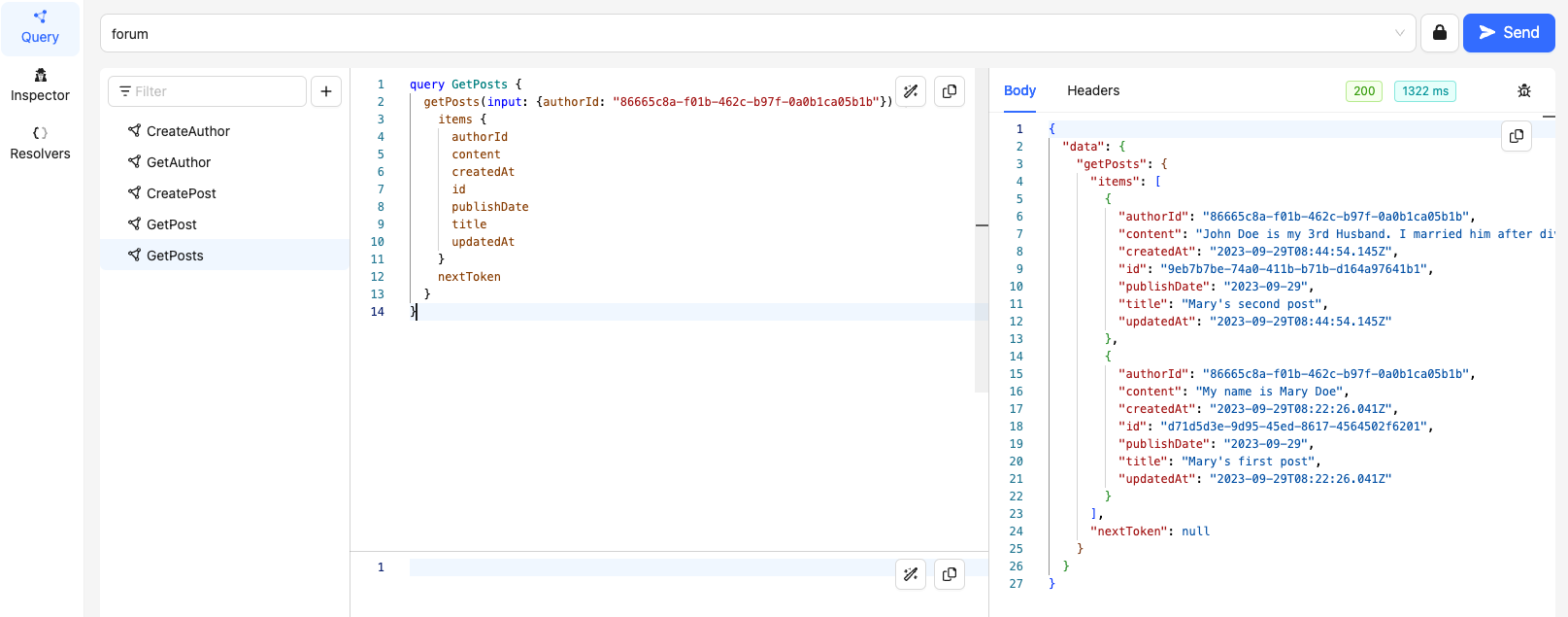
'GetAllPosts'
This query should return all posts made by all authors.
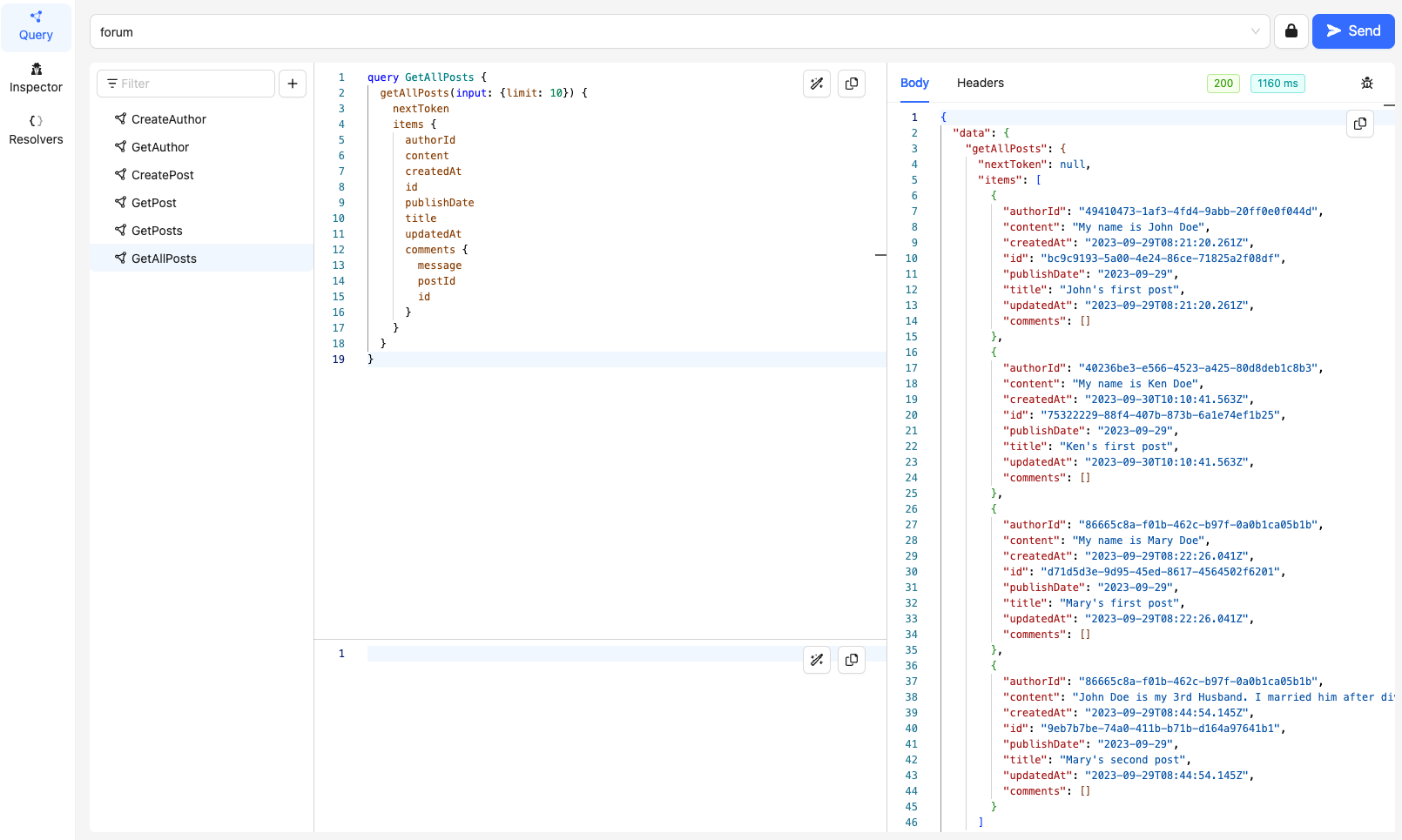
'CreateComment'
The mutation below will create a comment under a post made by Mary Doe:

There are a few other queries that can be run such as the Delete and Update queries but you can try that on your own.
Bonus
Just like with the other CloudGTO Blueprints, you can also have a head start test cases that cover a few basic test scenarios which you can later expand or eliminate depending on your personal scenario. Before using the AWS AppSync Console or GraphBolt to create GraphQL requests and responses with mock data, you can use the AWS SDKv3 for JavaScript 'EvaluateCode' API command to test your resolvers.
You can run the tests with 'npm run tests'
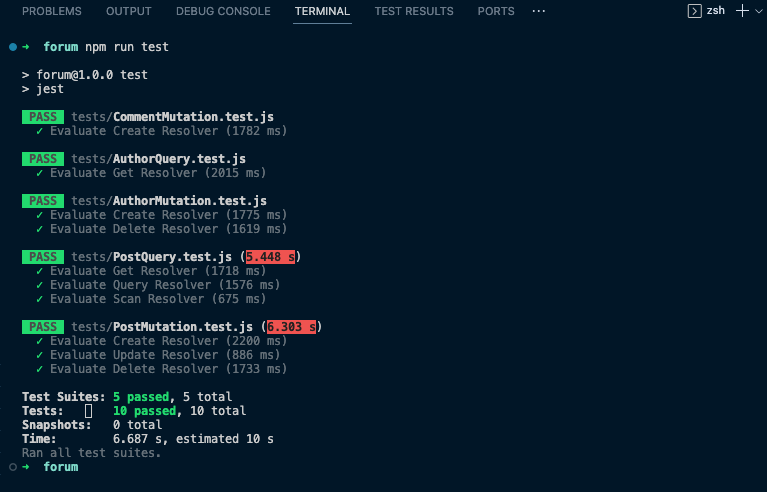
Conclusion
We’ve had a deep dive into the new DynamoDB Multiple Data Sources Blueprint and built a project on CloudGTO. We’ve tested most of the resolvers to demonstrate how the Blueprint can be used to quickly start the development of the same or similar GraphQL API projects with similar data models. Instead of taking weeks to build the infrastructure, CloudGTO could give you a day’s or even week’s head start so you can focus more on the application code and business logic which are the real differentiating factors that might guarantee the success of your application.
To ensure the efficiency and accuracy of our GraphQL operations, we leveraged GraphBolt—an intuitive desktop tool designed to simplify the testing of AWS AppSync APIs. This enabled us to validate our API's functionality and performance with ease.
It's worth noting that CloudGTO is currently available in public beta, offering you the chance to explore its functionalities at no cost. You can experience it firsthand by visiting cloudgto.com. The development of new features is an ongoing process, driven by feedback and insights from the community. If you're keen on seeing more use cases, we encourage you to contribute your feedback and help shape the evolution of CloudGTO.



%20(1).svg)

.svg)









.webp)