

Getting started with DynamoDB is fairly easy since there are a lot of examples and good documentation out there, but it’s as easy or even easier to end up using it wrong, due to a lack of knowledge.
During the last few years, the vast majority of mistakes I’ve seen have been due to misunderstandings or a lack of knowledge of how DynamoDB works and the differences between NoSQL and SQL databases.
This article aims to provide a brief introduction to DynamoDB and showcase the most common mistakes during its implementation and how one could solve them.
DynamoDB 101
The key aspects of DynamoDB could be described as follows:
- Managed NoSQL database by AWS: Designed to handle large volumes of data with low latency.
- High availability and automatic scalability: Automatically adjusts to demand without manual intervention (When configured to PAY_PER_REQUEST).
- Consistent millisecond performance: Ideal for applications that require fast response times.
- Supports flexible data models: Includes document and key-value tables, with secondary indexes for efficient queries.
- Global security and replication: Provides encryption and data replication across multiple regions for greater durability and availability.
Key differences: SQL vs NoSQL
| SQL | No-SQL | |
|---|---|---|
|
Data Model |
Relational - Tables with rows and columns |
Documents, Key-value, ... |
| Schema | Fixed Schema - Requires definition | Flexible and Dynamic Schema |
| Queries | SQL | System Specific |
| Scalability | Vertical | Horizontal |
| Data Consistency | ACID (Atomicity, Consistency, Isolation, Durability) | Eventual consistency to improve availability and performance |
The table above shows what I personally would consider the key differences between both Database types since, if you’re not aware of them, you’ll probably end up using one of them wrong.
For example:
- Schemas - No-SQL Databases don’t have a strict or predefined schema, meaning that you can store a mix of data types and structures in a single table.
- Data Consistency - In order to allow for high performance and availability, No-SQL databases are, in general, not capable of providing the data consistency we’re used to with SQL.
Both of these examples are key things to keep in mind when choosing which database best matches your project; as No-SQL and DynamoDB in particular might not always be the right fit for you.
Key Difference SQL vs DynamoDB (Example)
A part of the differences is how they are built and how they work under the hood. It’s also important to consider the differences in how services can interact with the databases since, as stated above, No-SQL DBs tend to rely on system-specific query languages.
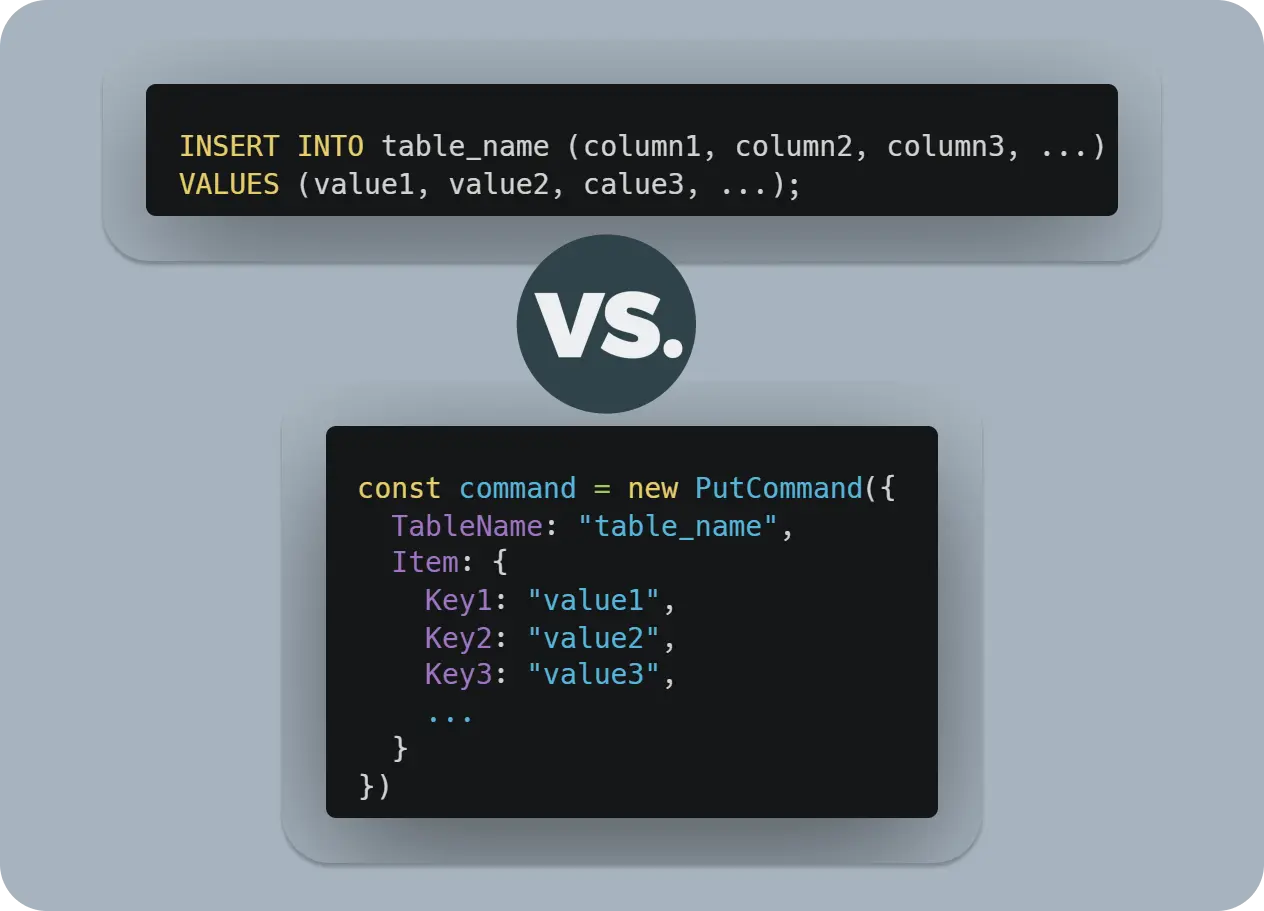
For example, 'INSERT INTO' in SQL and 'PutCommand' on DynamoDB will behave differently, and not knowing the default behaviors of the systems you interact with can land you in what seems like inexplicable bugs.
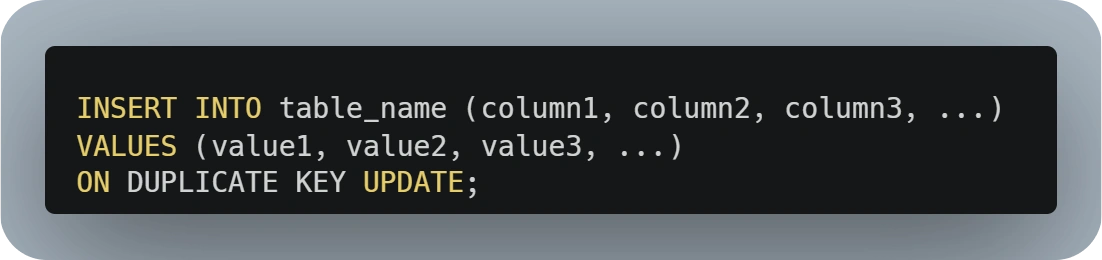
What we mean by that is that the 'PutCommand' and 'UpdateCommand' on DynamoDB will, by default, behave like an 'UPSERT' command in SQL.
This means that if developers are not careful enough or there is a lack of validations before performing the action, you might end up overwriting records (losing data!) or with downstream errors created by records without all the required attributes (records wrongly created by an 'UpdateCommand').
Avoiding this behavior can easily be done by adding conditions to those commands.
Condition Expressions
Condition Expressions could be seen as the DynamoDB implementation of the 'WHERE' clause, but limited to execute over only a single record.
Introduction
Using Condition Expressions allows developers to specify what conditions should be met for a given action to be performed.
For example, if we want to avoid DynamoDB default UPSERT behavior on 'PutCommand' and 'UpdateCommand' it would be as easy as adding a condition to the command.
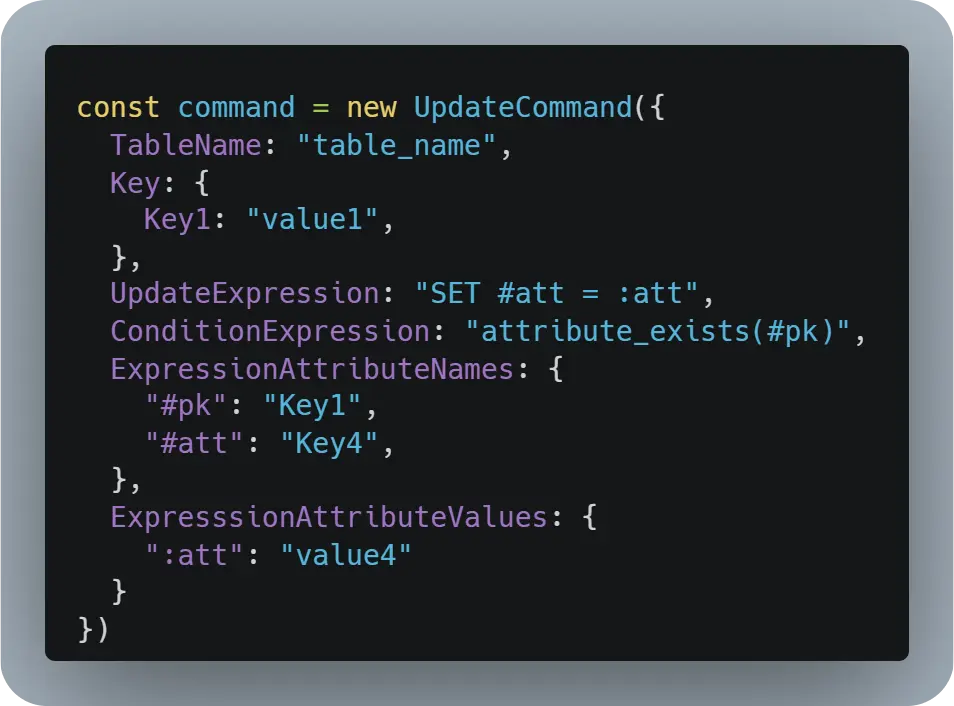
In the above example, we added a 'ConditionExpression' to the 'UpdateCommand' to ensure that DynamoDB only updates records where the primary key exists (aka. it will only update existing records and fail if no record was found for the given keys).
💡 Any attribute names and values used inside of a ConditionExpression will also be required to be specified under the ExpressionAttributeNames and ExpressionAttributeValues.
Idempotency Checks
But the usage of Condition Expressions doesn’t stop there. For example, it allows us to streamline the implementation of idempotency checks.
Idempotency checks are usually used to avoid processing a single event more than once. This becomes especially useful on distributed or event-driven applications where, in most cases, a single event could be delivered more than once or two consumers could be processing it at the same time.
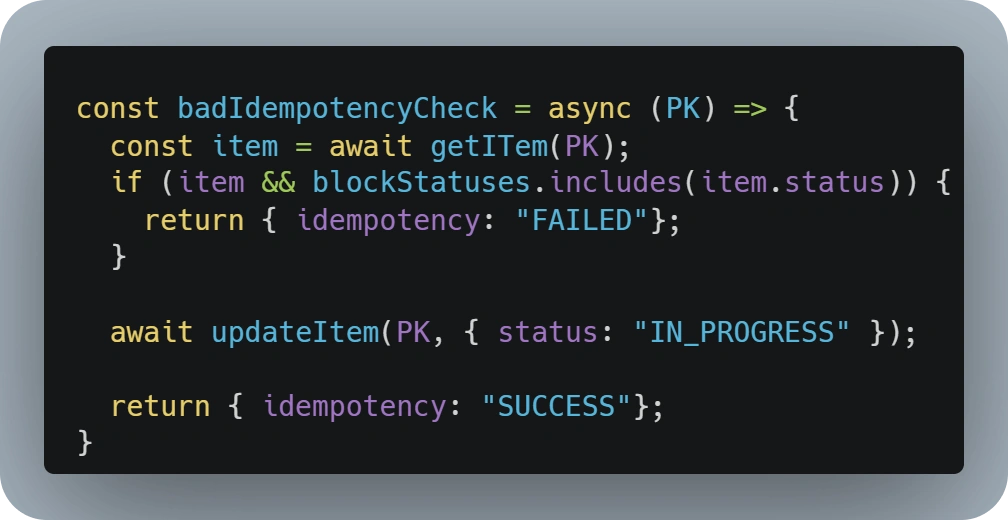
The usual implementation of this kind of check is using a database or cache to store a record for every event that has been or is currently being processed.
This means that the first step for a consumer Lambda would be to:
- Check if the Event has already been processed
- Update the databases stating that the given event is currently been processed
The screenshot above depicts what we would call a bad idempotency check implementation as it is being done with two different DynamoDB operations and we can’t ensure that this will stop concurrent processing of the same event, as there will be a time lapse between the read and the write operations.
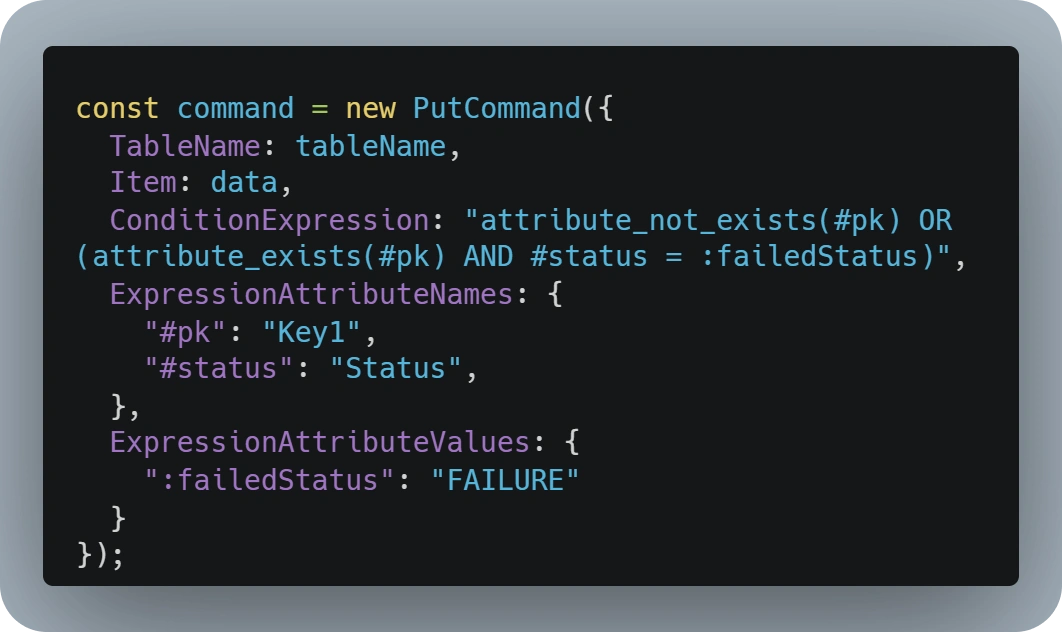
The correct implementation of an idempotency check using DynamoDB would be by using only one operation, either a 'Put' or an 'Update' command would work depending on if we need to persist any attributes stored by a previously failed execution.
The above sample implements a 'PutCommand' with a condition expression that will only succeed if:
attribute_not_exists(#pk)- This will only be true if no record is found for the given primary key, as it’s a mandatory attribute
OR
attribute_exists(#pk) AND #status = :failedStatus- This condition will only succeed if a record was found but the status of the previous execution was set as 'FAILURE'. Implementing this additional check allows us for seamless retries of failed executions.
Business Logic Checks
Condition Expressions not only allow us to implement idempotency checks, it also allow us to implement a condition on any 'Put' or 'Update' command.
Another good scenario for it could be the backend of a given marketplace, where we would need to perform some business logic checks before a given transaction is approved.
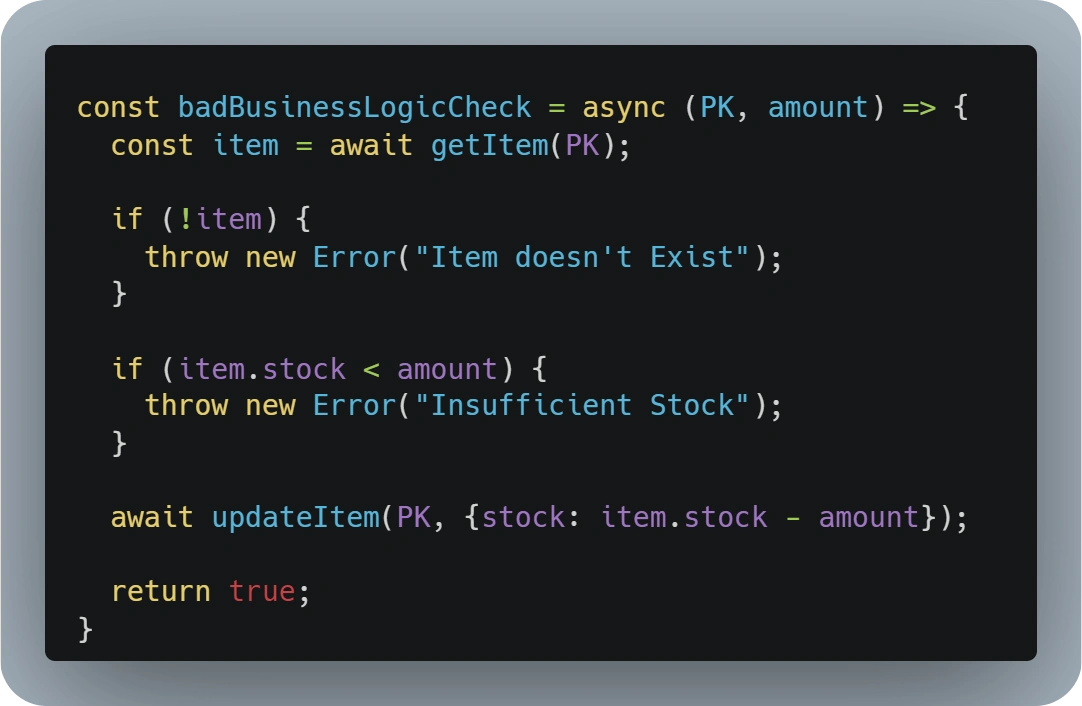
Similar to the previous scenario, developers might be tempted to implement the business logic as part of the code by making a read operation, performing any business logic, and finally making an update operation to store the final value.
This implementation would be flawed and probably generate some hard-to-find bugs in high-traffic scenarios, as no consistency can be ensured between the read and write operations and a wrong stock amount could be stored.
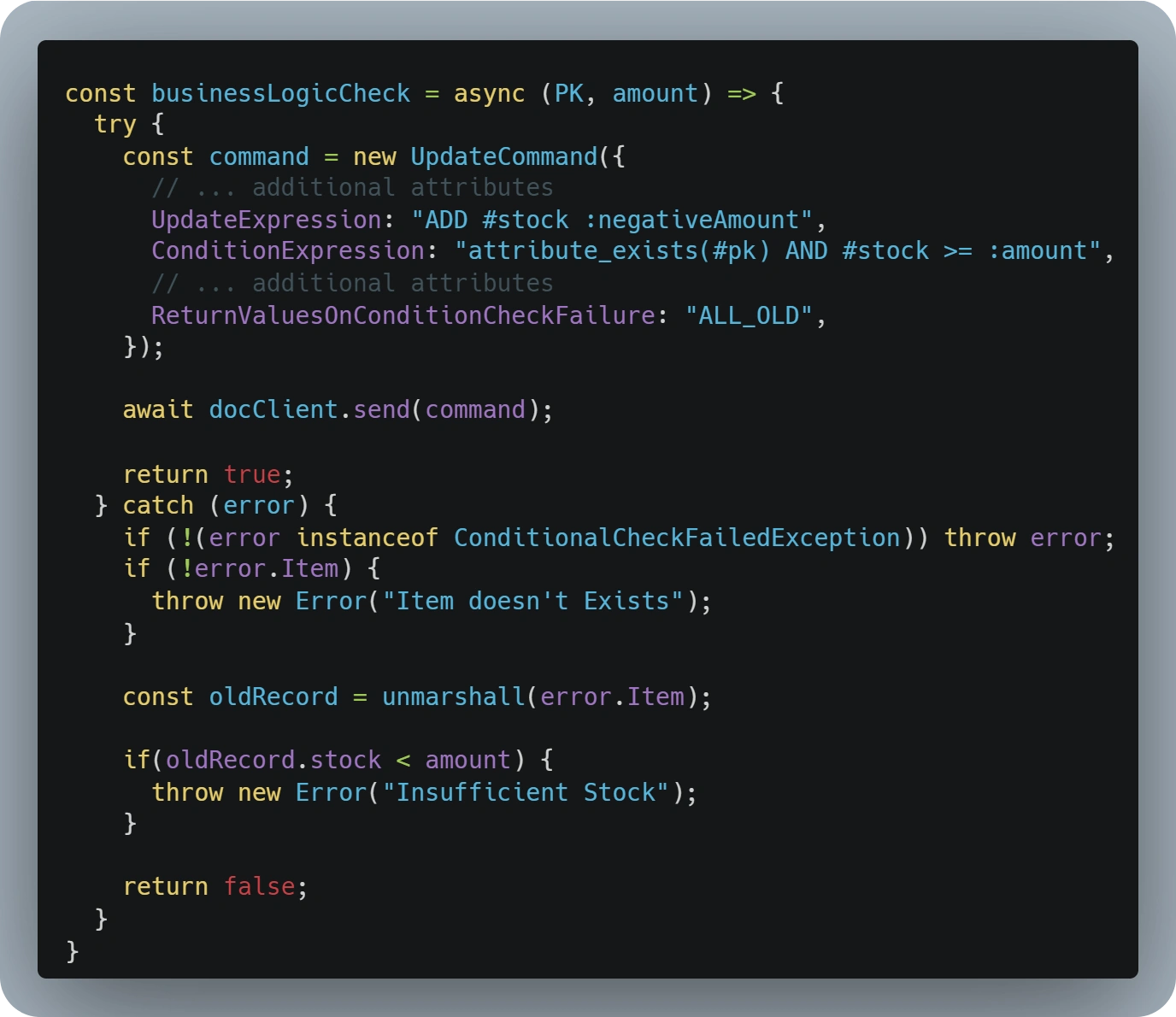
A better approach to this would be using Condition Expressions and, if there is a requirement for specific error messages, adding the 'ReturnValuesOnConditionCheckFailure' to 'ALL_OLD'.
By configuring your DynamoDB request that way, DynamoDB will throw a 'ConditionalCheckFailedException' if the 'ConditionExpression' is not met and provide the record details as it were when the condition was analyzed.
Developers would be able to access the 'error' and 'error.Item' to run any additional logic and choose the appropriate error message, based on what part of the condition could have failed.
💡 Do you want to learn more about DynamoDB Condition Expressions? Feel free to head over to this article covering them in more detail
Retrieving Data
Similar to 'Put' and 'Update' operations, No-SQL DBs also present a different behavior regarding how developers are expected to handle the retrieval of data.
Limitations
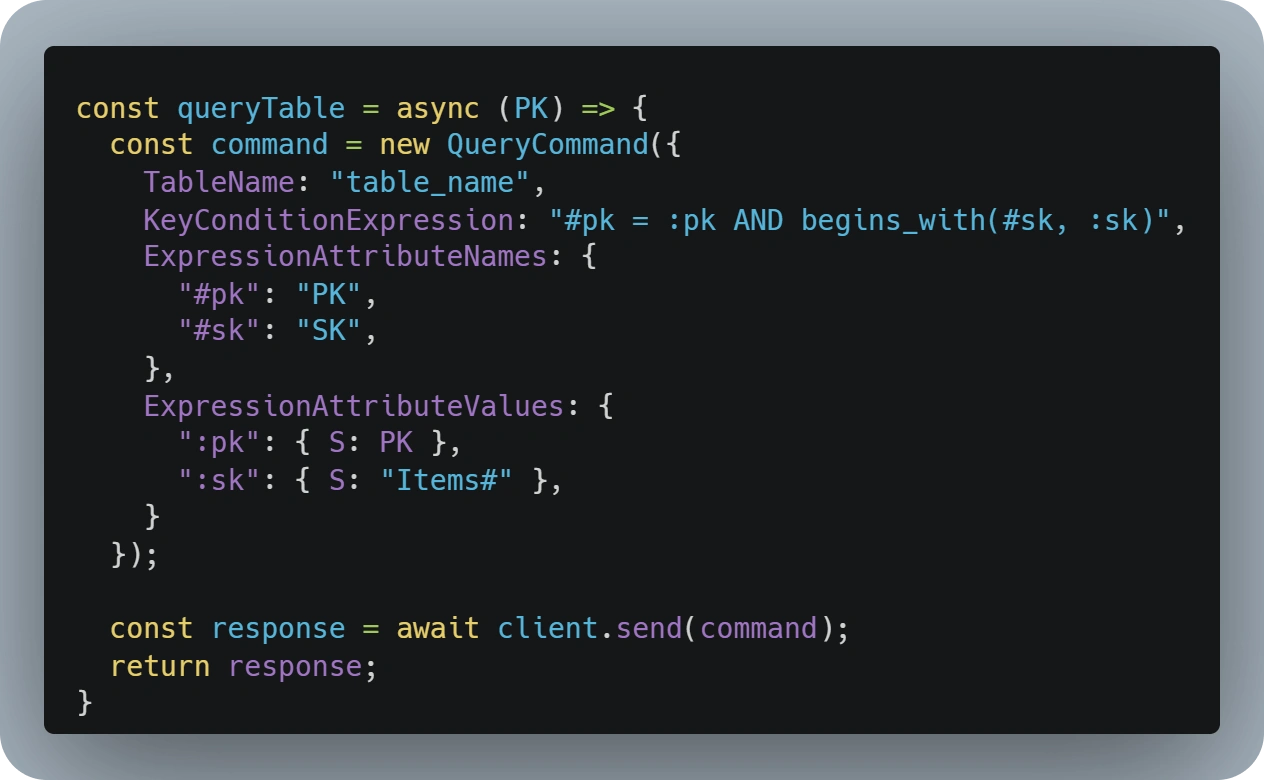
The most known limitation is that No-SQL databases perform poorly with access patterns and queries over attributes not part of the keys.
A part of that, and similar to the 'LIMIT' statement in SQL, Scan and Query operations can only retrieve up to a maximum of 1 MB of data at a time.
This presents a limitation for those cases where you need to retrieve more information or, especially, if you pass any type of query condition to your request, as DynamoDB will analyze up to 1 MB and could for example return an empty response even if matching records are present in the table.
Pagination
To overcome that 1 MB limitation, developers are expected to implement pagination.
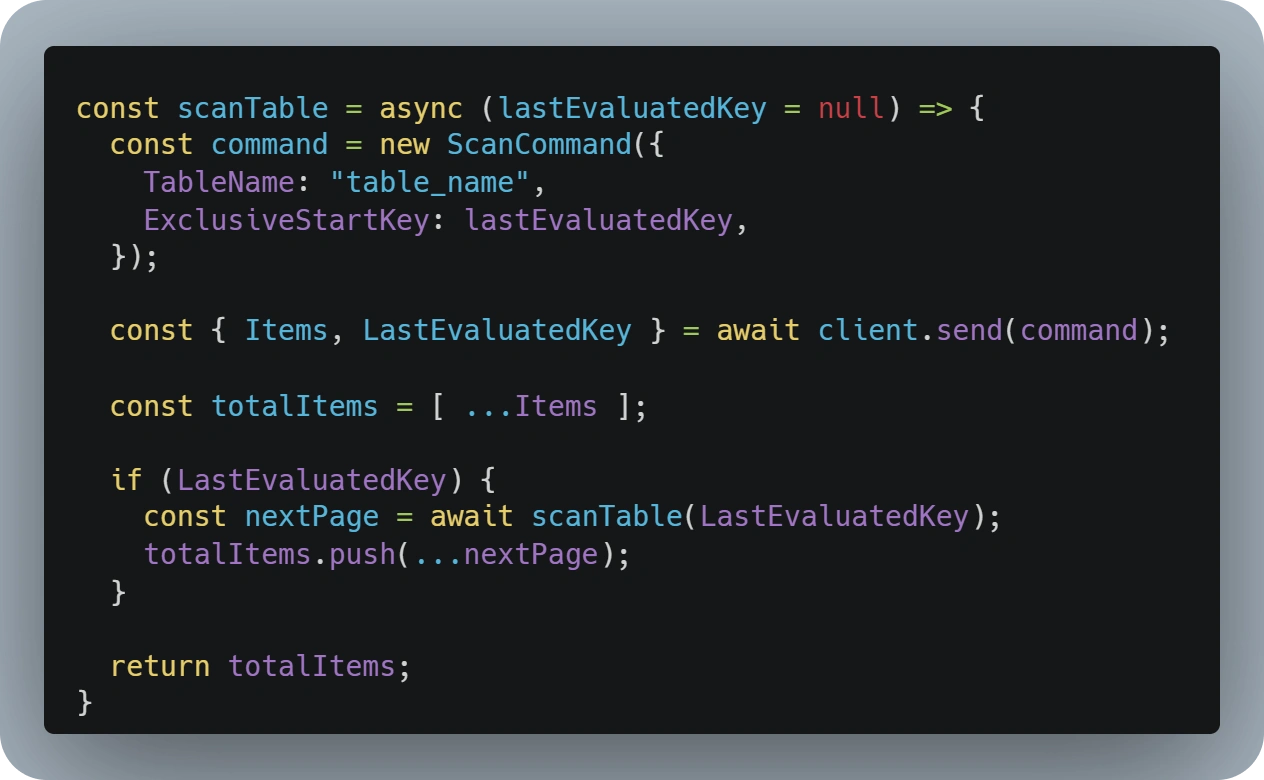
Implementing it is as easy as checking for the 'LastEvaluatedKey' attribute in the 'Scan' or 'Query' response and passing it as the 'ExclusiveStartKey' in the next request.
If this is developed as a recursive function, as shown in the above sample image, developers will ensure that all the records in a table or all records that match a specific query will be found and returned.
Batch Operations
'Put', 'Update', 'Query' and 'Scan' operations are the most well-known operations, but there are also scenarios where there is a need of writing or reading multiple specific records at once.
Limitations
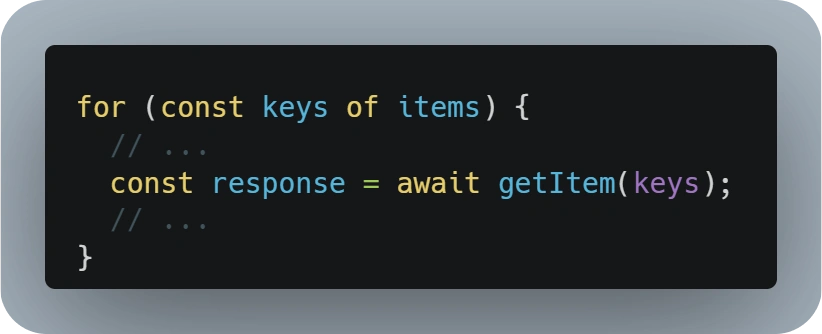
For those scenarios, people usually think of implementing a loop or multiple requests in parallel, which triggers are usually not the best approach.
On one side, having a loop retrieving information is usually already flagged as a bad practice by linters with rules like 'no-await-in-loop' from ESLint.
This is due to the poor efficiency of having all those requests in sequence, which will increase the overall execution time of the function exponentially.
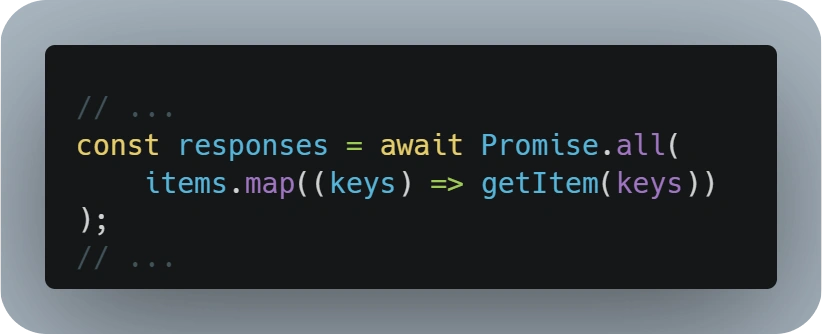
On the other side, developers might think that retrieving the data in parallel with a 'Promise.all' or 'Promise.allSettled' might be a good approach but this will also not scale well and be difficult to debug, as developers could face a maximum connection limit reached error.
The correct implementation would be to take advantage of the available Batch* operations of DynamoDB.
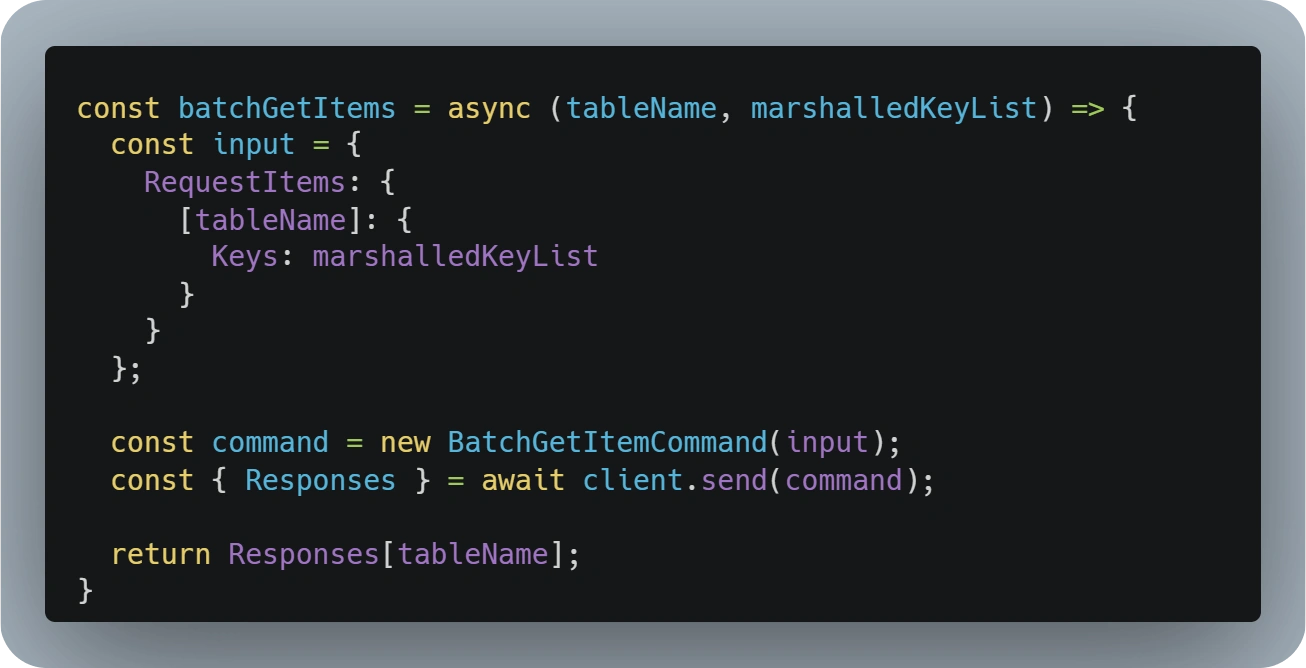
There are two different batch operations that can be used with DynamoDB:
BatchGetItems- Operation that will allow us to retrieve up to 16 MB or 100 records from the same or different tables in a single requestBatchWriteItem- As the name implies, this operation will allow us to write (PutRequest) but also to delete (DeleteRequest) up to 16 MB or 25 records to a single or multiple tables.
These operations are especially useful to aggregate multiple 'GetItem' or 'Put/DeleteItem' requests into a single call to DynamoDB.
Unprocessed Items
Similar to the Query and Scan operations and due to the 16 MB limit on the Batch* operations, developers should expect some requests to fail, either partially or entirely.
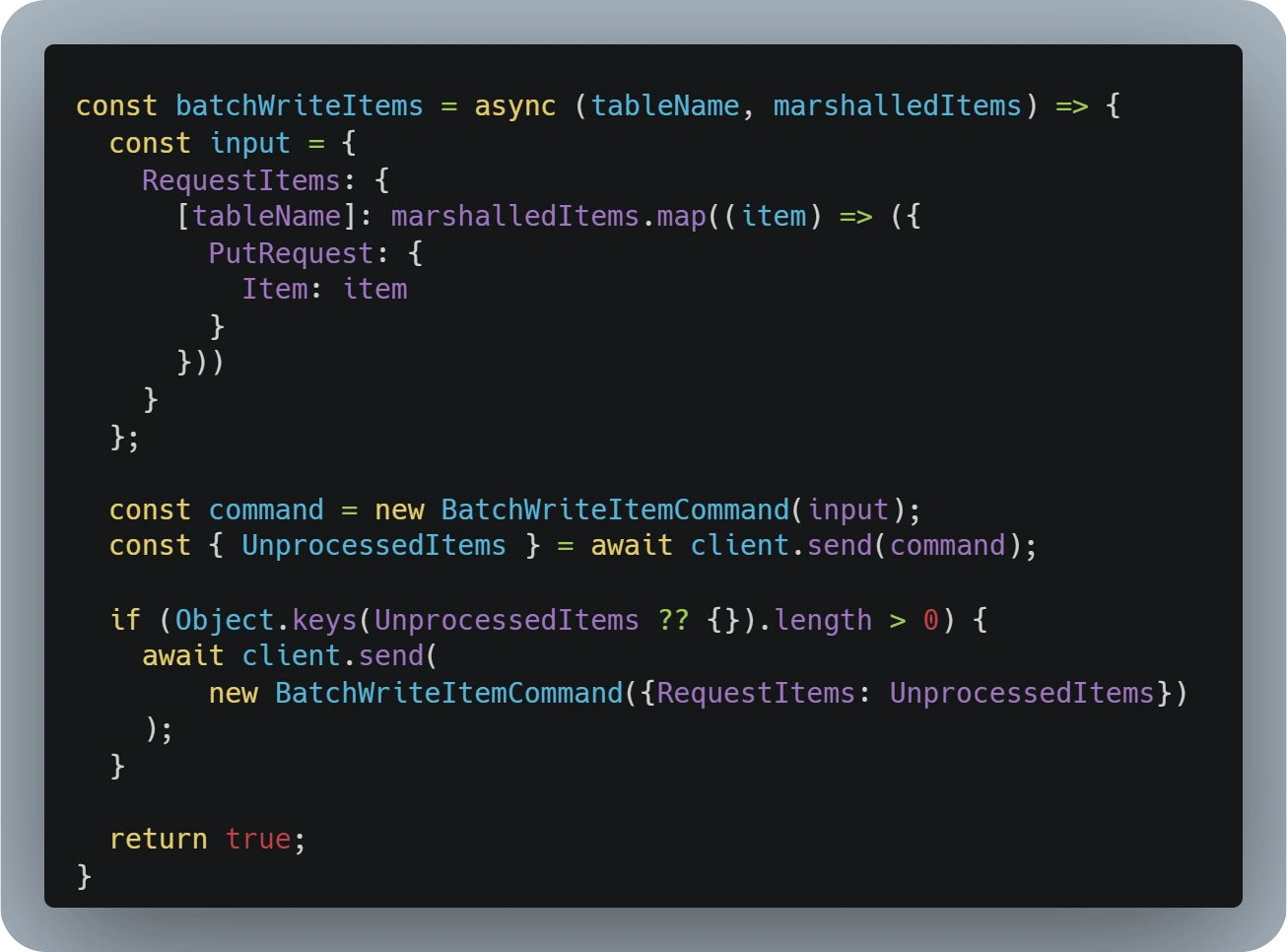
Any request that doesn’t respect the 100 record read and 25 record write limit will fail entirely, throwing an error without doing any modifications on the DynamoDB tables.
The 16 MB limit is a bit trickier, as one could expect those requests to fail partially, DynamoDB will do it’s best to read or write up to a maximum of 16 MB for a single request and, if any records are not processed, it will return those as part of the 'UnprocessedItems' attribute in the response.
Developers should always consider this when using these type of operations and implement a recursive function accordingly that will retry any 'UnprocessedItems' found in the response.
💡 Do you want to learn more about DynamoDB Batch Operations? Feel free to head over to this article covering them in more detail.
Conclusions
DynamoDB is a powerful and versatile NoSQL database that offers unique advantages for various workloads. However, to fully leverage its capabilities, developers must understand its specific behaviors and limitations. By mastering concepts such as condition expressions, pagination, and batch operations, developers can create more efficient, consistent, and scalable applications.
Developers should consider the following key points when implementing any workload that relies on or interacts with DynamoDB.
Key takeaways
- Put and Update act like UPSERTS: Using the PutItem or UpdateItem commands without adding any condition behaves like UPSERTS in SQL.
- Reducing calls with CONDITION EXPRESSIONS: Adding conditional expressions allows us to perform our logic in a single call and with data consistency.
- Query and Scan require paging logic: Query or Scan operations only operate on 1MB pages, paging is required to retrieve more information.
- Use Batch operations to reduce execution time*: A Batch* operation is more effective than multiple individual operations in sequence or parallel and can be used to aggregate operations to different tables into a single request.
- Use BatchGet to retrieve higher volumes of information: The BatchGet operation allows you to retrieve up to 16MB or 100 records compared to 1MB for Query or Scan operations.
- BatchGet and BatchWrite require retry logic: With Batch* operations it is essential to apply retry logic on UnprocessedItems.
References
- https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/Expressions.OperatorsAndFunctions.html
- https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/Query.Pagination.html
- https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/Programming.Errors.html#Programming.Errors.BatchOperations
- https://eslint.org/docs/latest/rules/no-await-in-loop
- https://lhidalgo.dev/unlocking-the-power-of-dynamodb-condition-expressions
- https://lhidalgo.dev/mastering-dynamodb-batch-operations-explained



%20(1).svg)

.svg)









.webp)