

Scenario
When triggering the API Gateway to retrieve information from the backend, the Lambda function typically handles all the necessary logic, such as fetching data from DynamoDB. Once the logic is completed and the Lambda reaches the "return" statement, it sends the response data back to the client. This process may take 8, 15, or even 25 seconds. During this time, while waiting for the data, you can add a loading animation to the frontend app. However, have you ever considered obtaining data in chunks and displaying it on the frontend in real-time? This way, users won't feel like they are waiting for the entire dataset. Achieving this is possible with Lambda stream response.
What is Lambda Stream Response?
For your Lambda function, you can configure a function URL that turns the Lambda into a stream response, allowing you to stream payloads back to the client.
## Features Provided from Lambda Stream
- Usual response size of lambda is 6MB, with stream response you can send up to 20MB.
- The streaming rate for the first 6MB of your function’s response is uncapped.
Implementation.
In this implementation, I'll create two Lambdas: one with regular response and another with stream response. We will then compare the results to determine which is better. To do this, I am using the Serverless Framework. Let's start with the steps.
Step1: Run the "serverless" command to create a project with a starter template. Then, go to the serverless.yml file and create two functions: one for lambdaBufferResponse and another for lambdaStreamResponse. Attach the API Gateway to lambdaBufferResponse so that we can trigger the Lambda from Postman. Also, create an IAM role for both Lambdas, allowing them to scan DynamoDB.
Below is the IAM role specification for both Lambdas, which should come under the Resource section.
Step2: As we've created the required Lambdas and permissions, let's create the function URL for lambdaStreamResponse to allow streaming responses with payloads.
Step 2.1: Create a response stream and attach the Lambda ARN.
Step2.2: we need to allow the lambda on how user can call this function url, using IAM auth or NONE, for now Allow the Lambda to be called publicly with NONE as the authentication type.
Step3: Once all the required templates are created, let's code the logic. For this, we'll have two Lambdas. First, a Lambda that scans the DB records and returns the response as a regular Lambda would.
Step3.1: this lambda will scan the db records and return the response as regular lambda do.
Step3.2: To enable the Lambda function for streaming responses, we utilize two crucial keywords: 'awslambda.streamifyResponse()' as the initiation point and, subsequently, 'responseStream.write()' and 'responseStream.end()' for managing the streaming process.
'awslambda.streamifyResponse()': it should be placed at the beginning of the function. It accepts a callback function with three parameters:-
- events:- This parameter holds the event data passed to the Lambda when triggered.
- responseStream:- Utilizing this parameter, you can write responses to the client and conclude the response; it serves as a writable parameter.
- context:- This parameter encompasses context details related to the Lambda name and other relevant information.
After integrating 'awslambda.streamifyResponse()', the Lambda function becomes aware of its streaming capabilities. Subsequently, you can proceed to implement your logic. Once your logic is complete, concluding the response is achieved by invoking 'responseStream.end()'.
In my logic below, I initiate the response with 'responseStream.write' after receiving the first chunk from the database response. This process persists until the entire scan is completed.
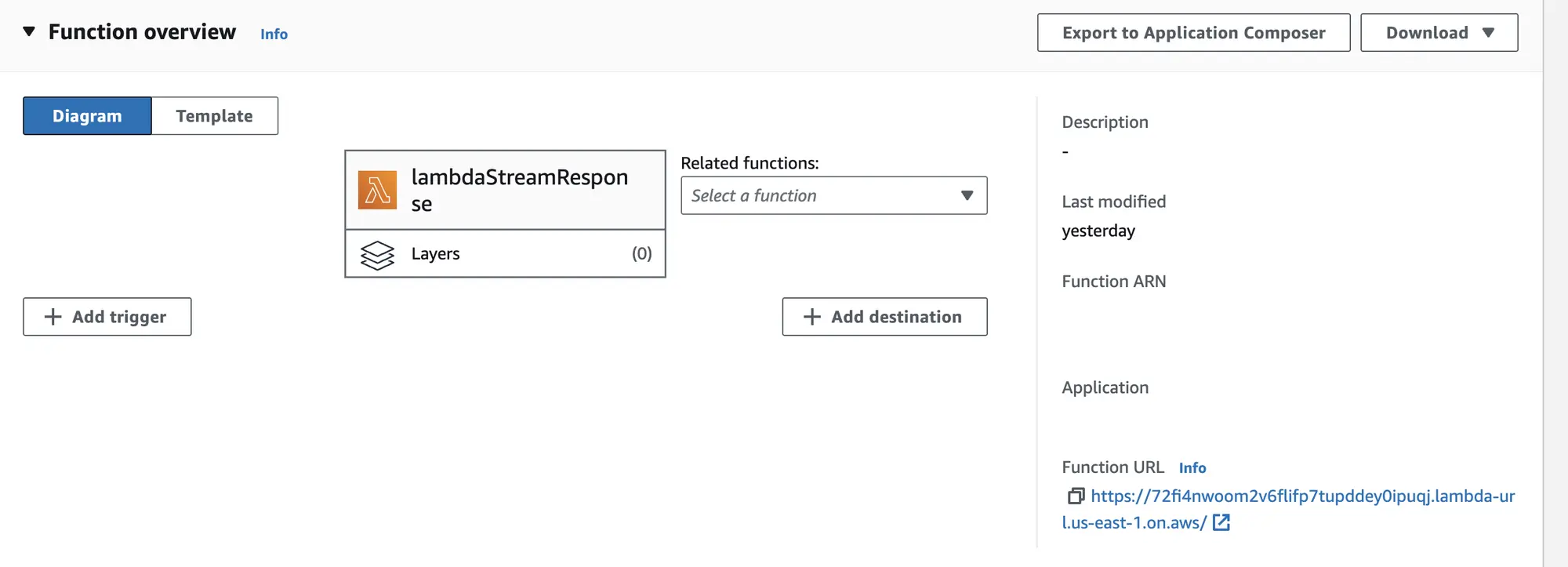
Step4: Deploy the project. Once deployed, go to lambdaStreamResponse in the function overview to find the Function URL. Using this URL you can call your lambda
Normal Lambda v/s Lambda Stream
let's first see how much time normal lambda does take. Normal Lambda
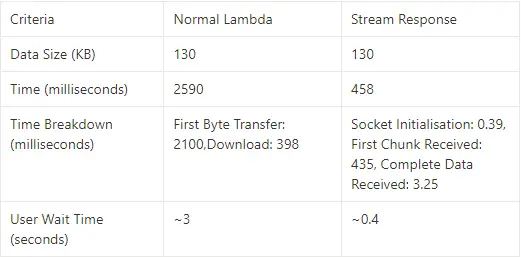
- When I triggered the Lambda through the API Gateway we created, it took 2.59 seconds to fetch 130KB of data, as depicted below:
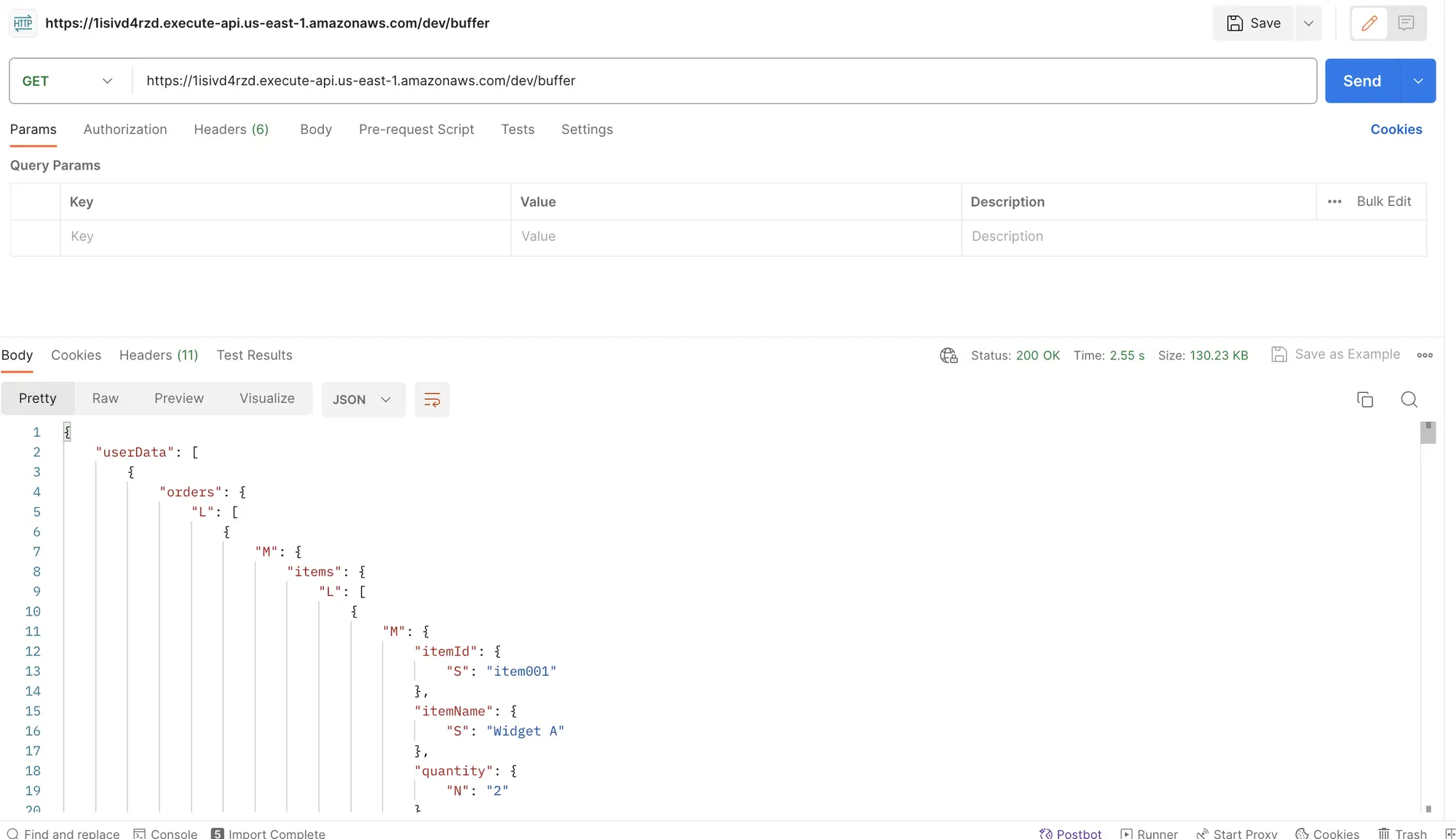
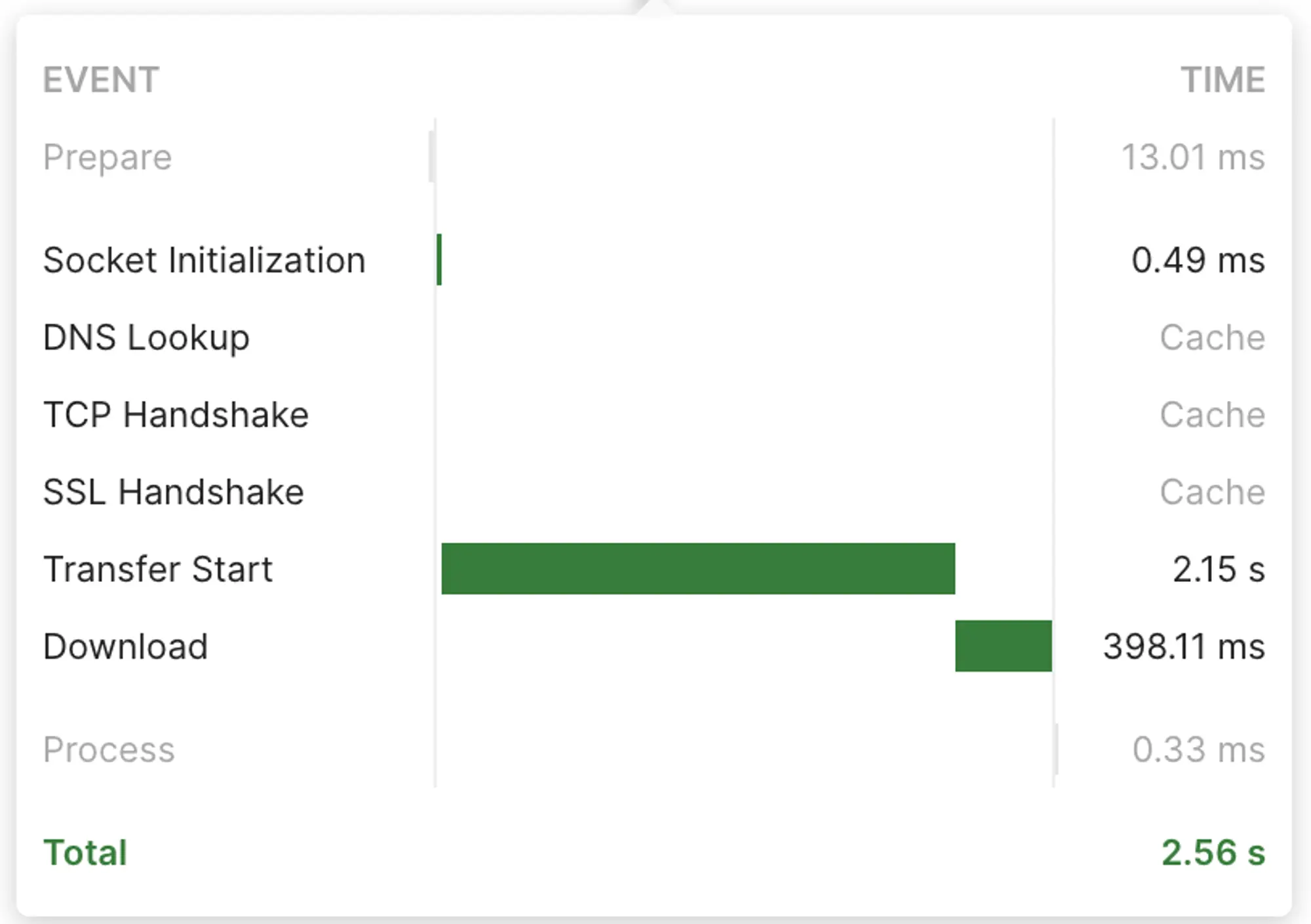
- A breakdown of the time reveals that the first byte transfer initiated at 2.1 seconds and completed the download in 398 milliseconds, resulting in a total time of 2.59 seconds.
- Users would need to wait for approximately 3 seconds to visualize all the data mapped for display on the frontend.
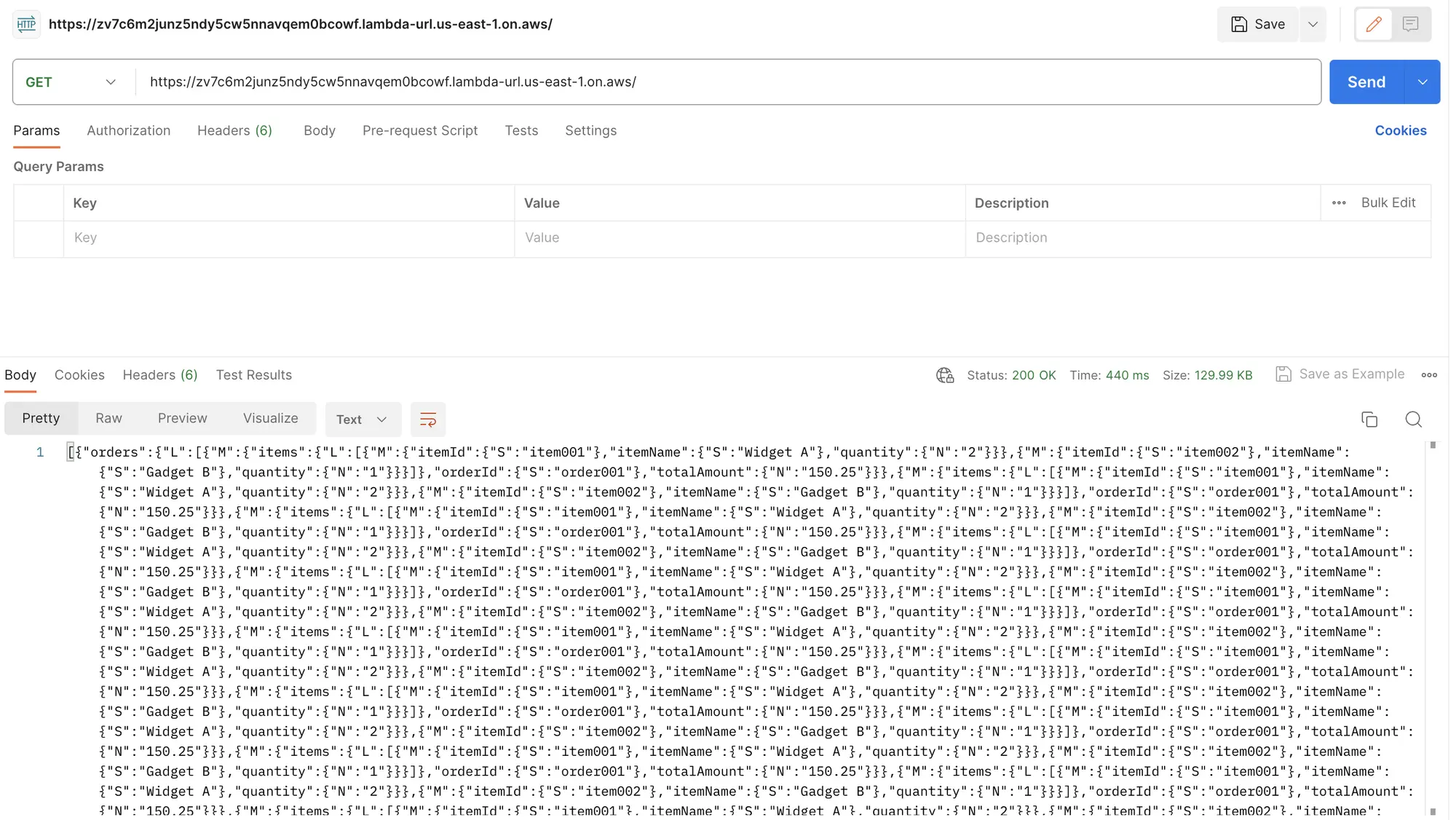
Stream Response:
- The stream response, on the other hand, took only 400 milliseconds to entirely fetch the 130KB data.
- Breaking it down, socket initialization began at 0.39 milliseconds, the first chunk of data was received at 435 milliseconds, and the complete data was received by 3.25 milliseconds.
- In total, it took 458 milliseconds.

Summary:
In conclusion, The Stream Response method significantly outshines the Normal Lambda approach in terms of responsiveness and user experience. The Stream Response not only fetches the data substantially faster but also minimizes the user wait time, making it a more efficient and user-friendly option for data retrieval in serverless architectures.
Social:
LinkedIn: https://www.linkedin.com/in/kishan-s-68baa9214/
Twitter: https://twitter.com/am_i_kishan
Reference:
AWS Doc: https://docs.aws.amazon.com/lambda/latest/dg/configuration-response-streaming.html
AWS Blog: https://aws.amazon.com/blogs/compute/introducing-aws-lambda-response-streaming/



%20(1).svg)

.svg)









.webp)